Last time, I compared SQL Server storage to Databricks storage. This time, let’s compare SQL Server compute to Databricks compute.
How SQL Server Processes a Query
When you submit your workload to SQL Server, the engine will first parse it to ensure it’s syntactically correct. If it’s not, then it fails and returns right away. Next, it takes several steps to determine the optimal way to answer your query based on what it knows about the data using indexes and statistics. The result of these steps is an execution plan. This plan is a set of tasks the engine takes to assemble your requested results.
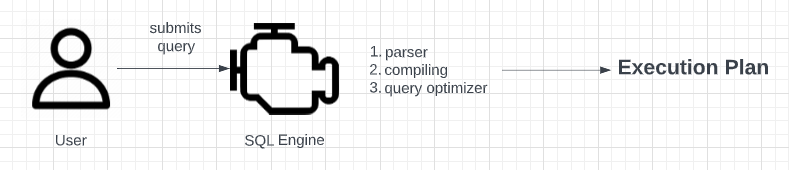
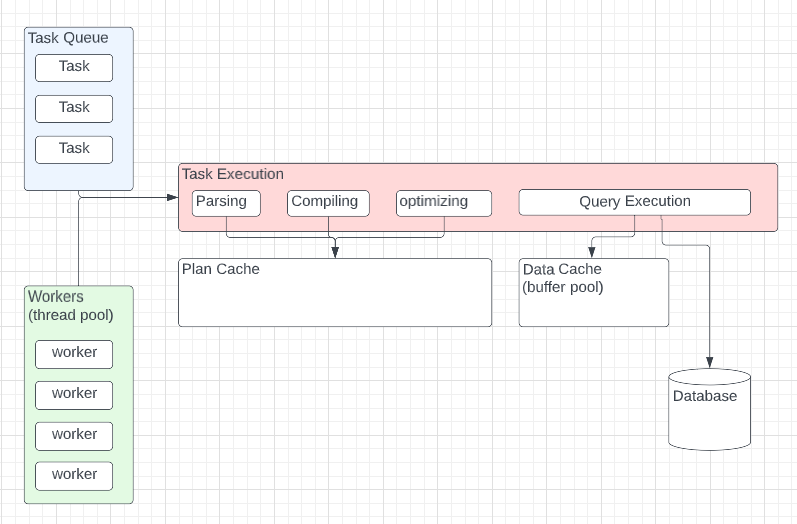
These tasks are then entered into a queue and are assigned to workers as they free up from other tasks. The more cores your SQL Server instance has, the more workers (threads) can run simultaneously. If a given task is a data retrieval task, it will first look in the data cache to save time. If the data cannot be located there, it goes to disc. Once all the required tasks for a given query are complete, the results are returned to the end user.
SQL has made a few attempts to provide scale-out functionality, but success has been limited. The limit we eventually run into is that you can only have so many cores available to your SQL instance. If you wanted an “easy” scale-out, you had to buy into SQL PDW (parallel data warehouse). The cheapest buy-in was a little over a million USD. This offering did make its way into Azure as Azure SQL DW. That offer saw little user adoption as well. Other attempts took more developer investment, such as Azure SQL Elastic Database. In the end, most found no good option for scale-out support with SQL Server.
How Databricks uses Spark to process a Workload
Databricks clusters are running Spark. That means you’re dealing with a set of Java virtual machines. In Databricks, you can write your workload in Databricks SQL, Python, Scala, or R. Spark (and its extensions) and translate each of these languages into Java for execution.
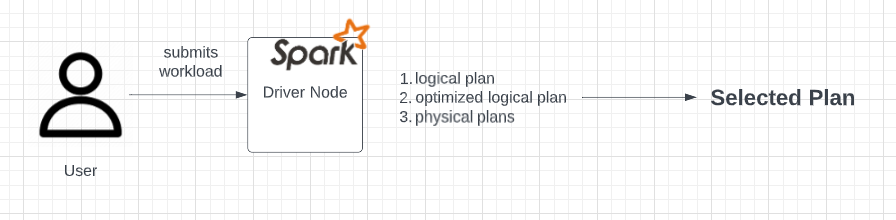
When you submit your workload to a Databricks cluster, that code is presented to a particular node called a Driver. The driver creates our spark session, our entry point into Spark, and then breaks our user code into tasks. This mirrors how the SQL Engine first decomposes a query.
Once the driver has this series of tasks, it starts handing out the tasks to other nodes in the Databricks cluster called worker nodes. The worker nodes are also Java virtual machines. These nodes have dedicated resources: CPU, Memory, storage, and networking. They also directly reach out to storage and can also store results locally in cache. In cases where you have to combine the results from multiple worker nodes, these worker nodes can cross-communicate to exchange data payloads.
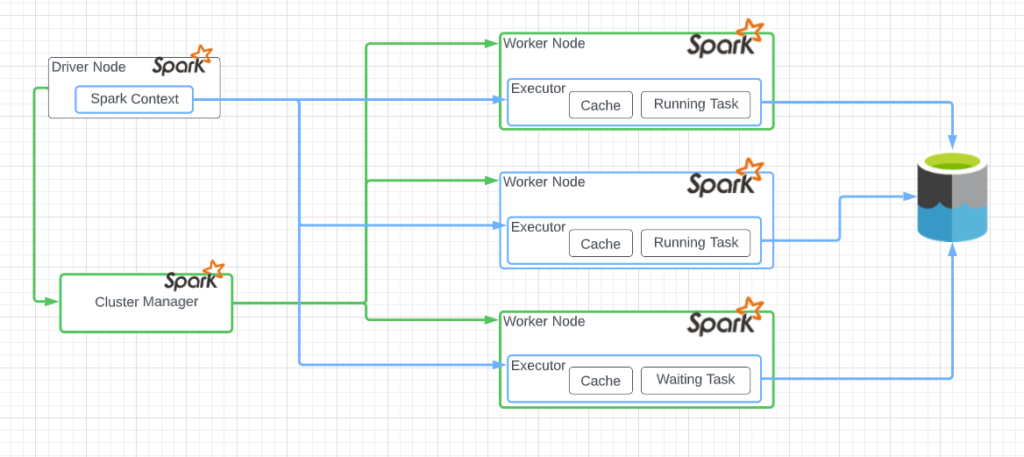
One of the fundamental assumptions of Spark nodes is they can fail. Based on that assumption, the driver node regularly checks in with another executable called a cluster manager to check the status of the worker nodes in the cluster. If a worker node takes too long to respond, a driver and cluster manager can handle these faults and respond to them based on an administrator’s configuration.
This design allows you to scale out to as many nodes as you can afford. Just keep in mind more is not always better for a given workload.
Also, given Databricks is a cloud-hosted solution, you can also scale up driver or worker nodes. The only catch is all worker nodes have to be the same size. You can’t have one worker node with 16 cores and the rest with four cores. You can, however, host multiple clusters in your Databricks environment. That way, you use the best-fit cluster for a given workload.
Update: Databricks offers a learning academy with many courses offered for free. I highly recommend the Introduction to Apache Spark Architecture course. It should take about an hour to go through. It uses an example workload of taking bags of little colored candies and eliminating all the brown candies. It turns out to be a great way of explaining how spark works.
Conclusion
Fundamentally, SQL Server was built as a single server. If you want more power, you scale up. Spark started from the assumption that combining many small, cheap servers could provide more horsepower. This is one of the more complex topics to understand when transitioning from SQL Server to Databricks. Once you have a few basics, you can dive in and start experimenting. Then pick up the rest as you go!
If you have any questions about how the two differ in processing, let me know!
Next time, I’ll dig into what data engineering looks like with Databricks. It turns out you can get started with just about any cloud-enabled orchestrator you can think of, so long as it has a connector for the storage service you’re using with your Databricks instance!