Spark engines like Databricks are optimized for dealing with many small-ish files that have already been loaded into your Hadoop-compatible file system. If you want to process data from external sources, you’ll want to extract that data into files and store those in your Azure Data Lake Storage (ADLS) account attached to your Databricks Workspace. In this demo, we will build a data pipeline to work with the New York City Taxi & Limousine Commission data.
Structuring Our Solution
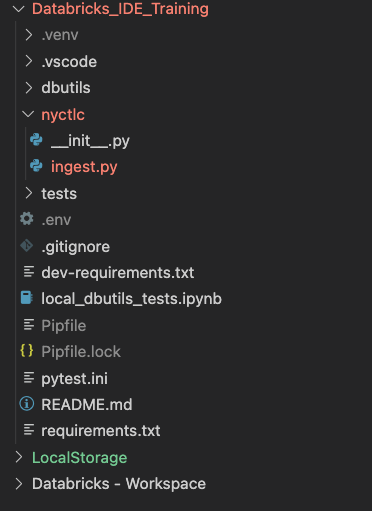
First and foremost, I advocate setting up a repository to work in. That way, if yo get into trouble, you can roll back changes line-by-line if nec ssary. Use whatever backend system you want to support this re sitory. In this case, I’ll spin up a repository named Databricks_IDE_Tr ining in my sandbox Azure Dev Ops acc unt.
Our solution will consist of a single Python package that contains several modules. The first package we’re go g to build is our ingestion package. We’ll need to create file and folders to begin this solution. First, we’ll add a folder to our local development folder named nyctlc. In that folder, we’ll add ingest.py. This is where our ingestion code will live.

Next, we l add a file to our local development folder called pytest.ini. This is where we’ll configure our project so we ca run tests. Adding the following ode to pytest.ini tells pytest that all our tests will be stored in files named test_<package name>.py.
[pytest]
python_files = test_*.pyFinally, we’ll add a folder for our tests and a file named test_ingest.py. This is where we’ll write our tests for our ingestion code.
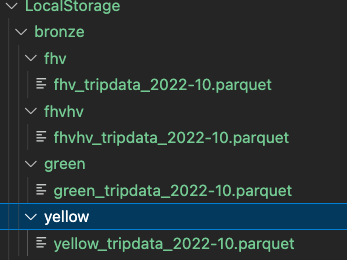
We’re also going to need a local folder to store data. This will be a stand-in for ADLS. I created a folder named LocalStorage and added it to my workspace to quickly access data files while developing the solutio
You’re ready to start writing code when your solution loo s like the screenshot.
Extract and Load Trip Record Data
Step one in our solution needs to be able to download the trip data. If you hit https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page you’ll learn a few essential details about building our first function. The source files are now in parquet format instead of CSV. Also, if you highlight over each link for the four source file types, you’ll discover they follow a pattern.
- Yellow Taxi trip records — https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_<YYYY>-<MM>.parquet
- Green Taxi trip records — https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_<YYYY>-<MM>.parquet
- For-Hire Vehicle trip records –https://d37ci6vzurychx.cloudfront.net/trip-data/fhv_tripdata_<YYYY>-<MM>.parquet
- High Volume For-Hire Vehicle trip records — https://d37ci6vzurychx.cloudfront.net/trip-data/fhvhv_tripdata_<YYYY>-<MM>.parquet
Databricks is best at ELT. That means some other process will be developed to move these source files to our bronze (raw) zone. I usually use Azure Data Factory to orchestrate these Extract-Load workloads. In this case, we’re just going to download these files to our LocalStorage \bronze folder to emulate that work.
Remember in datalakes, all files in a given folder are expected to be compatible schemas. So in our case we load each file to a matching folder where more files of that schema can land. For example, all fhv_tripdata files go into the folder /bronze/fhv.
Transform Trip Record Data
Parquet file format is nice. It’s compressed, and optimized for high row volumes. The only thing that could be better is Delta. We can add schema and ACID compliance and audit history to our data store. In this transform code, we’re going to write some code to transform our data from Parquet to Delta files and tables.
In the code snippets below, I’m excluding the in-code documentation for clarity. I follow the default PyLint suggestions for documentation, so every package, module, class, and method are commented. I also suggest comments for obscure code inside a module. Obscure is any code a junior programmer couldn’t understand by just reading the code.
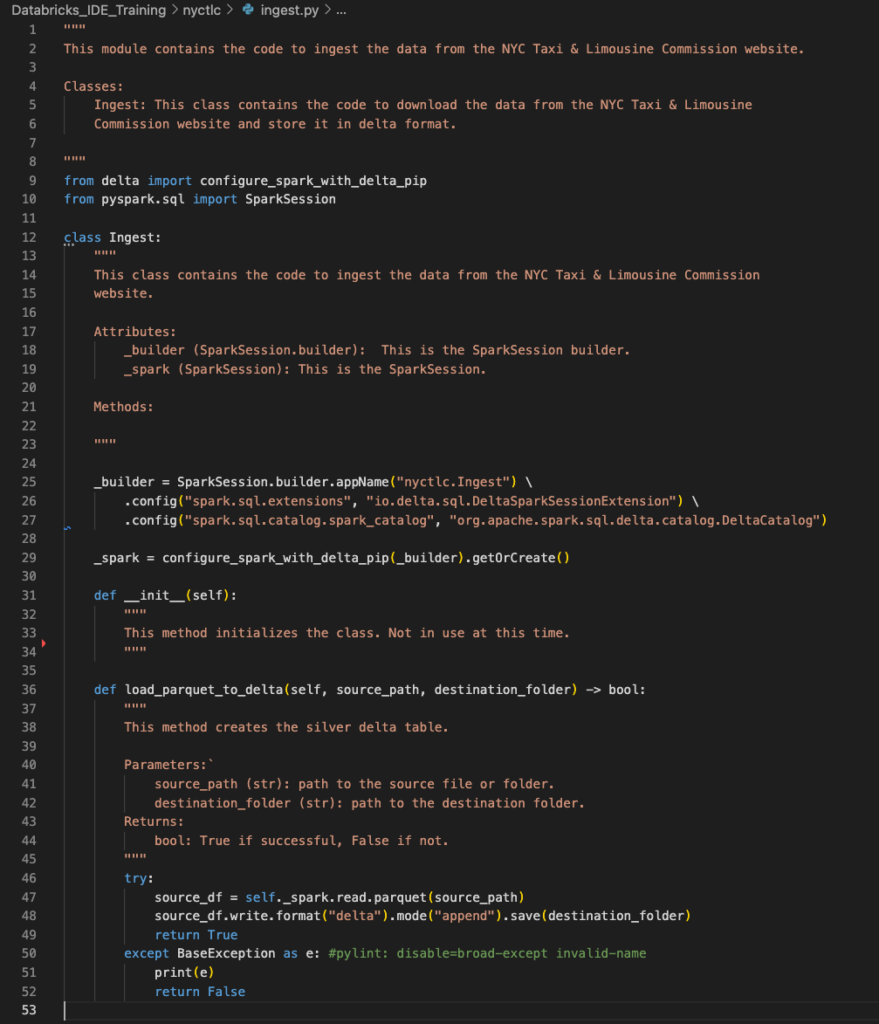
Let’s add two files to our nycltc folder, __init__.py and ingest.py. In the init file insert the following code.
"""
Import helper, list all nyctlc modules here as they're developed.
"""
from nyctlc import ingest
__all__ = ['ingest']
This file helps when you’re importing your new package. I’ve found pytest struggles to resolve packages and modules without this file. For now, this file will ensure we can import our new ingestion module we’re about to create. To use build python solutions around delta, we need to import two modules. We installed these requirements in the previous article.
from delta import configure_spark_with_delta_pip
from pyspark.sql import SparkSessionNext, we’ll stub out a class in our ingest module called Ingest. My practice is to name classes after the module file name. A module file can contain more than one class, in that case the classes are named <ModuleName_Functionality>. So in our Ingestion case, if I needed a second class to handle ingesting SQL Server sources, I’d name that Ingest_SqlServer. ClassNames are PascalCase.
class Ingest:Since our ingestion module runs spark and delta functionality, and to use those, you have to set up a SparkSession object, I set up two private attributes. The first is the SparkBuilder, the object that lets you configure the SparkSession, then the SparkSession instance itself. Private attributes’ names begin with an underscore.
_builder = SparkSession.builder.appName("nyctlc.Ingest") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
_spark = configure_spark_with_delta_pip(_builder).getOrCreate()Now we’re ready to add our first method. This method will read a source folder full of parquet files, then write that data back out in spark format. This example of transforming code is meant to illustrate the pattern. Our method only requires a source_path and a destination folder. The error handler is simplified at this point. In a real case, we’d build in as many error handlers to this code as we can uncover in the development process.
def load_parquet_to_delta(self, source_path, destination_folder) -> bool:
try:
source_df = self._spark.read.parquet(source_path)
source_df.write.format("delta").mode("append").save(destination_folder)
return True
except BaseException as e:
print(e)
return FalseHere’s the code as a whole.
Next Time
Next time, I’ll walk you through my approach for simultaneous code and test development. By taking this approach I can work through coding issues as I go, and when I’m done, I have tests that can be used for the deployment process to help me check my code before release!
If you have any questions, let me know.