If you work with CSV files, you know how important it is to have a clear and consistent schema for your data. A schema defines your data’s structure, format, and types and helps you validate, transform, and analyze it. The problem is CSV files have no INFORMATION_SCHEMA or similar metadata store you can query to…
Using Generative AI in Data Engineering
As a professional, I place a high value on my role as a data engineer, with consulting being a close second. My role requires both technical and interpersonal skills. I’ve come to depend on two AI-based tools to enhance both. Grammarly has helped me be cognizant of my tone and style of writing. Copilot has…
Getting started with Microsoft Fabric
A few weeks back, Microsoft announced its newest data offering, Fabric. After spending a little time with marketing materials, documentation, and some hands-on time I’ve learned a few things. The short version is this is just the next step of Synapse. Where Synapse merged Azure Data factory, SQL Data Warehouse, and a spark engine, Fabric…
Docker-based Spark
Recently a client mentioned he wanted to run spark in a container for testing Databricks code locally. He Was working from the basic docker-compose yaml file provided by bitnami. That way, the containers would run on his local machine. The problem was accessing the cluster from the host machine. I decided to take a day…
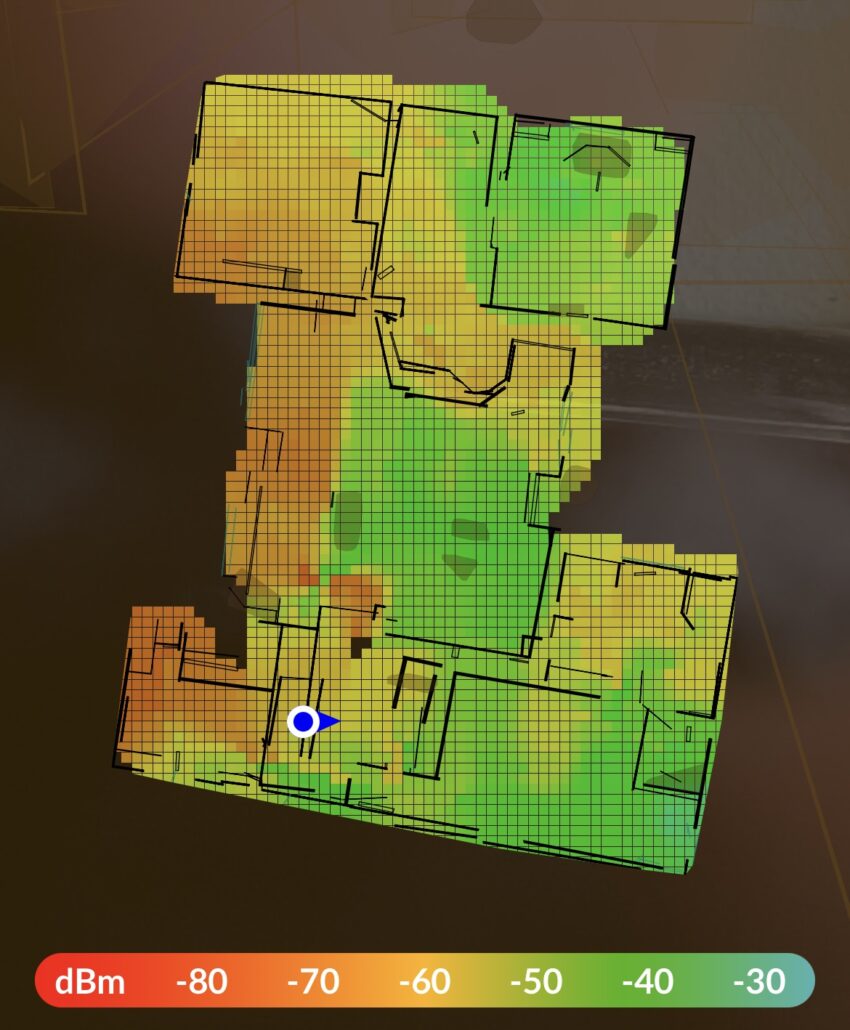
Network Infrastructure Updates
If you’ve tried accessing the site over the past couple of weeks, you might have noticed it wasn’t up 100% of the time. That’s because I was upgrading my network infrastructure. Before the migration, I ran the Ubiquiti EdgeRouter 6p. This is a tremendous little quad-core router that ran completely silently. I upgraded from the…
Docker and Watchtower
When I began work with SQL Server, I used to run a single Windows server with a single instance of SQL Server 2000. I used this instance to test code and configurations separate from my employer’s servers. It helped me verify if a change could help and by how much it could help. That single…
Delta Sharing – Data Providers
Setting up Delta Sharing in Databricks is straightforward once you understand the diagram provided in the Azure Databricks documentation. Delta sharing is implemented as a part of Databrick’s Unity Catalog. Unity catalog is the official data governance solution for Databricks. You can consider it an extension to the metastore catalog or Databricks version of a…
SQL Server to Databricks Profiler
Recently I had a client that expressed interest in migrating their data warehouse from Azure SQL DB to Databricks. They weren’t looking to move due to any performance issues in Azure SQL DB. They were running on the Hyperscale offering. They were looking to share a common data architecture between their data warehouse and data…
Delta Sharing – Data Recipients
Recently I was asked to look into Delta Sharing to learn what it’s all about and how it could be used. fter digging in a little bit, It appears that it’s a way to share data in parquet or Delta format. ou can build these shares on top of any modern cloud storage system like…
Metadata-Driven Python
You will manually build your ingestion code when you first learn to ingest data into any new engine. This makes sense; you’re just getting started. You want to learn how the engine will read the data and then write it back again. You want to learn how to log what’s happening during ingestion. You want…