Introduction
There’s a ton of data on the Internet. Some of that data is really easy to download and extract that data into a relational database. Data that comes in CSV, JSON or maybe even a database backup. Unfortunately, not all of that is as easy to get at. What we do in the only way we have to access that data is from an HTML file or collection of HTML files?

I first came across this problem almost 10 years ago, when I was working with a small company dedicated to centralizing all international trade data into a single database. The problem I was tasked with solving was gathering rules, regulations and tariff data into that database. So not only did I have to solve the problem of getting information out of HTML files, but HTML files that were generated by government agencies. If you’ve spent any time dealing with government data, you’ll know that raises the level of difficulty a bit.
The turning point in this project came after I began thinking of those HTML files as delimited text files. Very noisy text files, but delimited nonetheless. Once I realized this…data extraction came quickly.
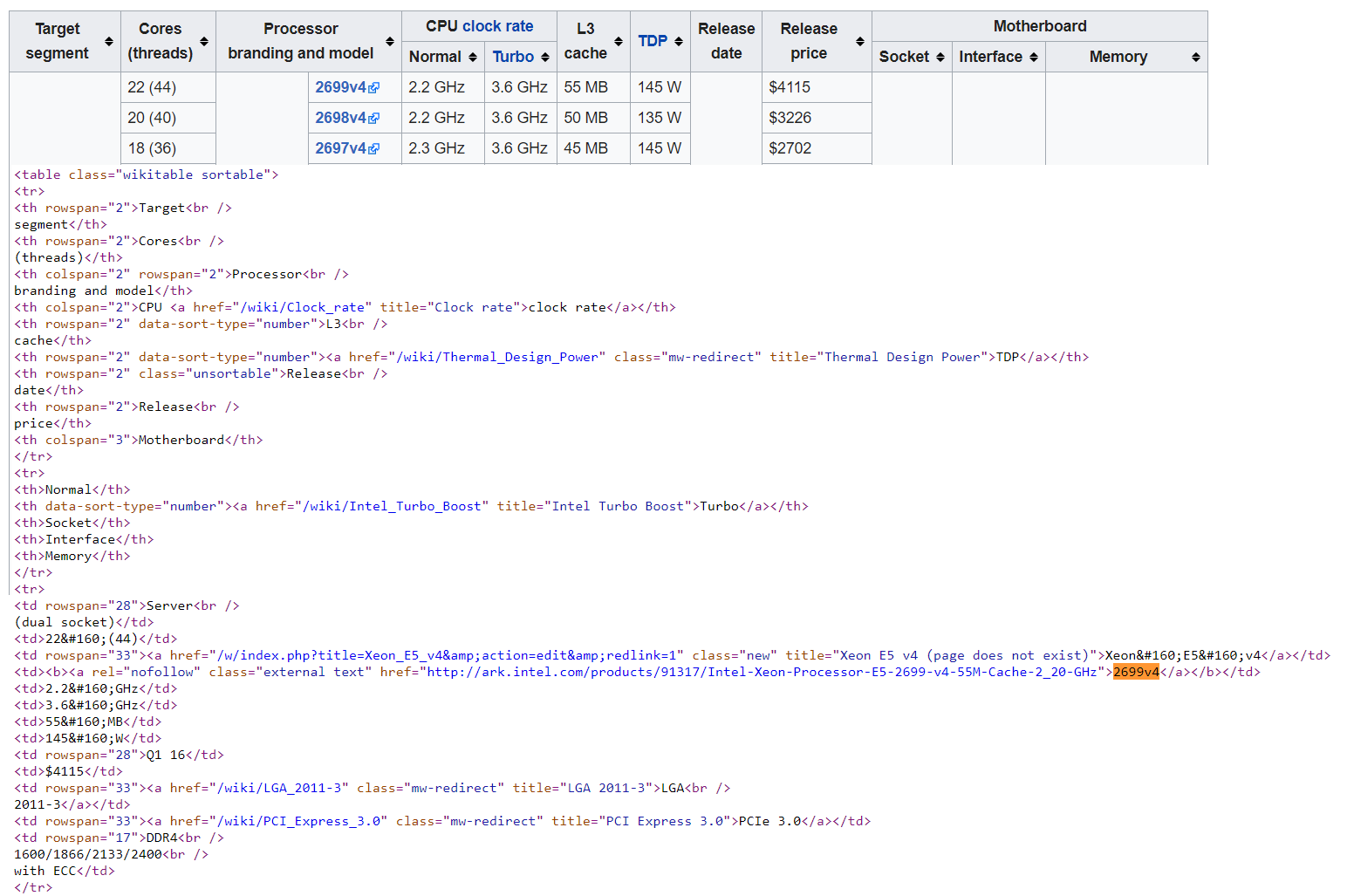
This is a table from Wikipedia showing attributes for Intel processors. While it’s not as simple as a CSV, there are delimiters. Each row of the table is a record. The delimiter for each row is <tr> at the beginning and </tr> at the end. Each cell in the row is an attribute of the processor. Each cell has a start delimiter of <td> and an ending delimiter of </td>. With this much information we can identify the data elements we’re interested in. Unfortunately, it’s not so simple you can use out of the box SSIS. Fortunately, Microsoft allows you to extend their tools with .Net script tasks.
One last note before we dig into the technical details…
Before we get into the details of how are going to do this? I’d like to stop and take this time to talk to you about the terms of service on websites. A lot of sites are going to be very protective of their data. It’s up to you to search the site and find out if you’re allowed to extract their data. Find the site’s terms of service read through it, and make sure its OK. Sites like Wikipedia are fine with you extracting their data, but sites like LinkedIn are definitely not going to be OK with this.
Solution Architecture
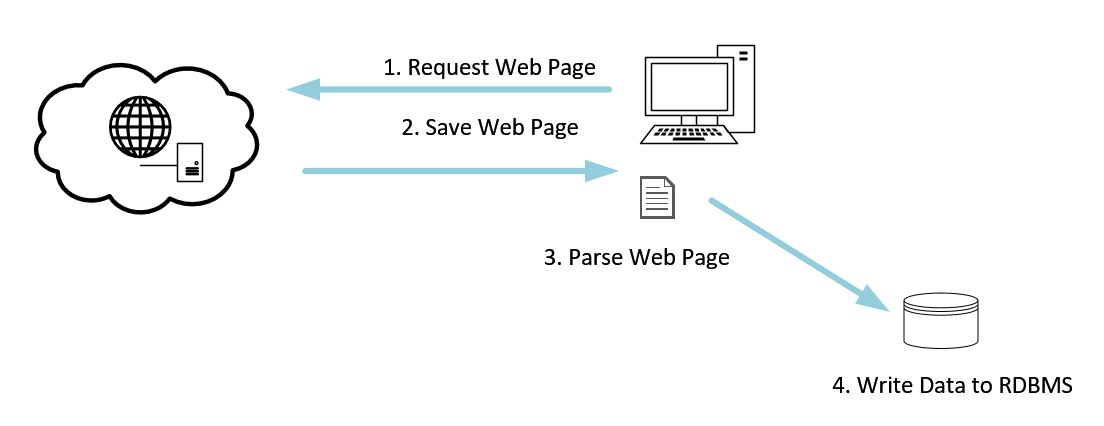
Getting data from web pages begins with a request to a web server. Every time you type in a URL into your browser, you’re requesting a page from a web server. The web server responds with a web page. We then save that file locally, and then parse that web page for data elements. Once we find those data elements, we then write those to our staging staging database.
The File Staging Loop
The most time is spent in that request and save loop (items 1 and 2). Even if you’re on gigabit, that web server is not just handling your request, but could be handling hundreds of thousands of requests for other users at the same time. Since this process is time intensive you will want to build one process that does nothing more than requests a list of web pages, and saves them to a staging folder to be processed further later.
This process also need to be smart enough to know. Hey, I’ve already downloaded this file before, and I shouldn’t downloaded it a second time. Otherwise you’re putting undue burden on the web server, and you could introduce duplicate data into your staging database. Neither option is appealing.
I suggest a log of what URLs you have processed and when they were last processed. This work log can be used to stop and restart your scanning (or crawling) of the source website. You could also extend this log to handle special cases where you do wish to download a file you’ve downloaded before. For example, you may find your source files change over time without updating their URL. Another use of this log is to allow parallelism on parsing your web pages after they’ve been downloaded.
Sometimes you’ll find there is a pattern to the URLs you’re interested in. For example: http://sourceServer.com/data/?recordID=1. http://sourceServer.com/data/?recordID=2, http://sourceServer.com/data/?recordID=3. The pattern here is each record’s business key is in the URL. I know if I request ever increasing business keys, I can get the next record. I can keep doing this until the server responds with an undesirable HTTP code.
HTTP Codes
When you get started with web based data, you’re going to need to get to know about special codes that can come back some times in addition to the web page you’ve requested. These codes can help you optimized or troubleshoot your solutions. Check out the official list over at IANA. The ones you’ll hit most of the time are 200 and 4** and 5** codes. An HTTP code of 200 is OK. Life is good. 400 and 500 codes are bad. I’m sure you know 404, not found. You’ll get that one if you request a URL that the server can’t find. 500 codes are bad because it generally means that the server messed up. If the IANA list is too long just remember:
- 20*: cool
- 30*: ask someone else
- 40*: you messed up
- 50*: the server messed up
The Parsing Loop
Items 3 and 4 in the diagram can also take up significant time too. If the html files are huge, and you have to read the whole document each time, parsing can run long. It can also take a long time if you don’t use any kind of parallelism to read multiple files at the same time. We’re going to dive into more details on how to build your parsing code in the next article. If you’ve dealt with web based data sources before, let me know, I’d love a chance to talk to you about your solutions!