As I began learning Biml, I developed my original metadata model to help automate as much of my BI development as I could. This model still works today, but as I work with more file based solutions in Azure Data Lakes, and some “Big Data” solutions, I’m discovering it’s limitations. Today I’d like to talk through one possible solution to this problem: abstraction. Before we get into that, I’d like to revisit my previous model in case you haven’t seen it before.
Current State
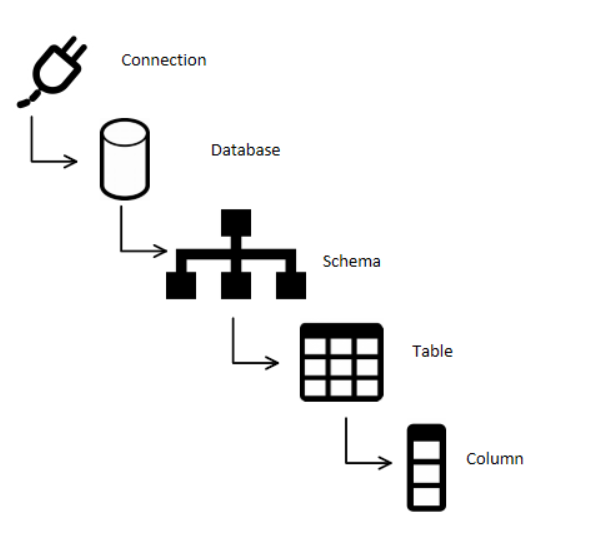
My model follows a hierarchy that will be familiar to anyone who’s spent time with Microsoft SQL Server. It all begins with Connections. You can have connections to database servers, files, or even an API endpoint. I have a connection type attribute on the connection that let’s me know what I can and can’t do with the connection. That’s important for choosing how to deal with a file versus dealing with a database.
When we move down a layer to Database, things have to be made to fit the model. When we’re talking about files, they don’t have a concept of database. They also don’t have a concept of Schema. In many of my solutions, I’ll use Database and Schema to refer to folders in a file path. A database will refer to one folder, schema will refer to a subfolder of that “database” folder. Then inside that “schema” folder you’ll find folders where every file in a given folder is of a given layout. All these files are to be processed into a given table in SQL Server.
But what happens when you don’t have a three folder deep path?
What if your connection is an API end point and each request is a different “table”?
I keep finding more and more situations where my metadata model is too limiting to my solutions. Fortunately, my concept of Table and Column fit nearly every situation I’ve come up against so far. Even if the name “Table” actually refers to a view, stored procedure output, or file’s contents.
New Solution
I struggled with how to extend my current model for a while. I’d understood object oriented programming concepts like objects, inheritance, and polymorphism, but they’d just become words developers used to explain how their code was so awesome. As I grew into more of a developer by building out my BI tool belt, these words started to make sense. In fact, they gave me a new idea on how to solve the metadata model problem.
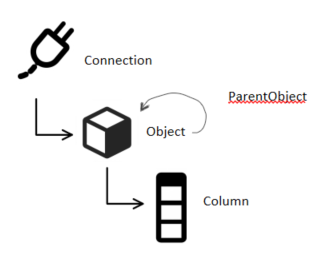
I kept my Connection records like they were, but I effectively combined my concepts of Database, Schema, and Table into a single concept: Object. An object in this new model has a connection, type, and optionally a parent object.
If I want to model a database, schema, and table, I can still do that! I just insert a row for the database into the object table, with a reference to it’s connection and type “database”. Then I grab SCOPE_IDENTITY() for that insert statement. That gives me the parent object ID I’ll use for the next insert: schema. I insert the schema name, connection ID, and the database’s identity value, along with a type “schema”. I grab the next SCOPE_IDENTITY() generated so I’ll have it for my table insert. Finally, I insert the table’s name, connection ID, and the schema’s ID, along with a type of “table”.
Then, when I go to model columns, I do that like I would for the previous model.
Now, when I want to model a file, I can model a connection to a single file with just a Connection record and a Object record. I could also model a complex folder structure full of files with multiple Object records of type “folder”.
I could also model a connection and data object for each API call I want to mine for information.
No more forcing a data model into an arbitrary structure. I now have flexibility!
Full Disclosure
I’m actually cutting over all my previous solutions to this new model to see if I can break it with existing examples. My hope is I can move my old solutions onto this new metadata model without breaking anything. I know I’ll have to rebuild my code that builds SSIS packages to get the data from the new model. I’m also moving all my new projects to this model too, since many more projects are file based now than they were before. If I find any examples that break this model, I’ll share my findings here.
If you have any thoughts on this model change, I’d love to hear them!
Until next time, keep on automating!