Understanding how Databricks works with storage can go a long way toward improving your use of Databricks.
Storage
In SQL Server, we store our data in two highly structured file types. The first type of file is a data file; these have an extension of MDF or NDF. You get one MDF per database, but you can have multiple NDF files if you want. These data files are broken down into extents, 64kb chunks of data composed of 8 pages of data. Each page contains a header, footer, and as many rows of data as can fit in that 8KB page.
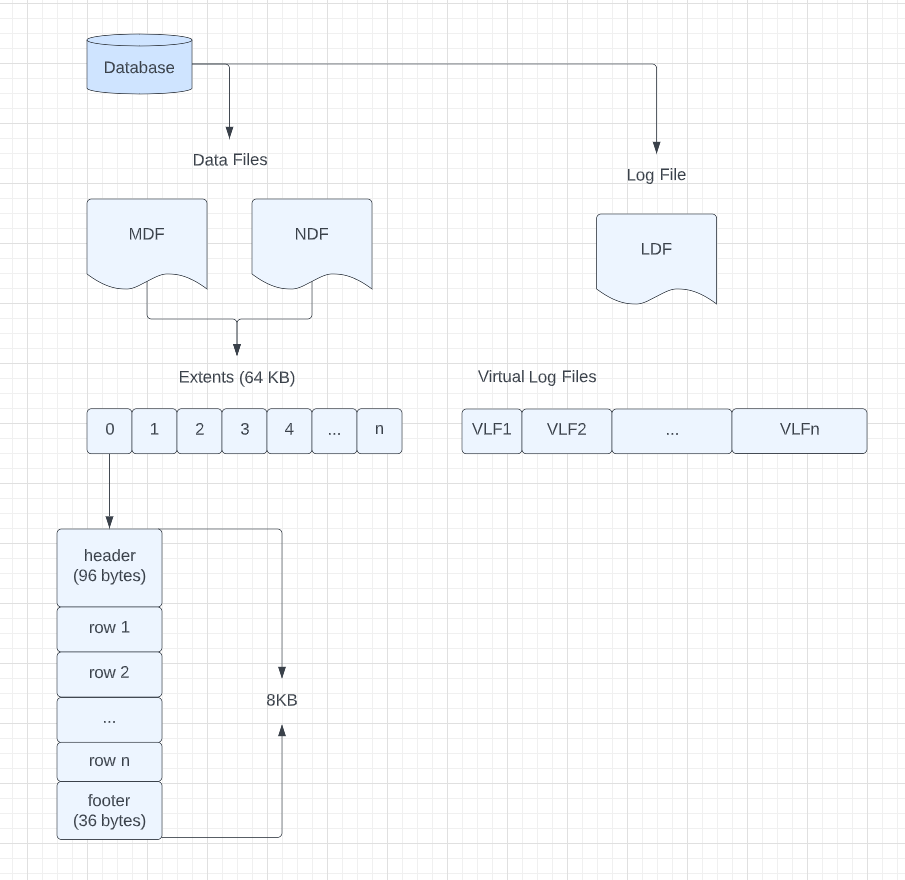
The second file type is a log file. This file contains a record of each data change operation performed in your database. How long that record sticks around is configurable by the database administrator. These log files are broken down into virtual log files of different lengths. While you can have more than one log file for a database, it provides no performance benefit and often complicates your management costs.
Storage and Performance
When using SQL Server, you may find that your performance is limited by storage performance. For example, you have a database that holds every sales transaction for the past 10 years. Currently, that database has a single data file. That data file is stored on a spinning disc (HDD).
You could first try moving that data file to a solid-state drive (SSD). That improves performance considerably, but queries still take a long time to complete. You dig into the queries further and discover that most queries deal with the past two years of data. Users rarely deal with older data.
You decide to add a second file group called archive. Then, you partition your sales table by month and year. Data older than two years is moved to the spinning disc, and new data remains in the primary filegroup on the SSD. Now, when users include dates in their query, which use the partition key on the table, they get significantly faster queries.
Following this example further, we could add additional filegroups and data files, along will additional drives. Each change could improve our IO performance up to a certain point. Eventually, you’ll find that you’ll end up moving your bottleneck from IO to memory or CPU.
Modern Storage Solutions for SQL Server
Today many of our SQL Servers are virtual, and the drives connected to them are too. They’re discs hosted in separate servers near our SQL Servers. The good news is most of those solutions abstract the physical discs that host your data. While you may see a single logical data drive in your SQL Server instance, that drive is 5, 10, or more physical discs under the hood. This means that you have access to more data throughput than if you had one physical drive.
This means you can choose an amount of throughput for your logical disc. And that speed is usually more consistent than a single drive would ever be. All of that is great news, and the bad news is now network latency will show up as IO latency in your database.
Databricks Storage and performance
Databricks takes advantage of this new modern storage solution. Rather than having a single disc, you connect to a file system, a Hadoop filesystem HDFS. This can be hosted in blob storage (ADLS v2), AWS S3, or GCP. When using HDFS, your data gets spread out among dozens, if not hundreds, of discs.
In addition to having so many discs hosting your data, you can also use semi-structured files. You can choose from CSV, JSON, AVRO, or Parquet. The benefit of using semi-structured files is you don’t have to model your tables up front. The downside is you’ll have to pay for that flexibility with additional CPU costs.
Databricks has added one additional file type, Delta. It’s built on Parquet but adds many amazing features to data lakes.
First and foremost, Delta brings ACID transactions to your data lake!
Let that sink in for a minute. That used to be the primary argument against moving from a database to a data lake. It’s gone now.
Delta also gives you schema evolution (just like JSON, AVRO and Parquet). But adds on the ability to perform schema enforcement. You can now enforce that schema and prevent bad data from being inserted in the first place!
Delta adds audit history, time travel, DML operations, and more. All of this is why you’ll start hearing the term Data Lakehouse more often in the future. This is how you deal with the four Vs today.
Please, take the time to read more about what Delta can do.
Conclusion
The way Databricks works with storage is similar to how SQL Server works with data today. It’s all remote storage you connect to via the network. The storage is abstracted. You’re guaranteed a certain amount of storage at a certain number of IOPS. In the case of SQL Server, you could still host that storage locally and pay for it through a combination of CapEx and OpEx. In the case of Databricks, it’s all OpEx. Pay for what you use, as you use it. You get flexibility in Databricks storage. But with that flexibility, you’ll pay a higher CPU cost.
In my next entry, I’ll show how SQL Server and Databricks handle queries differently. Until then, if you have any questions, let me know!