Since Databricks is a PaaS option for Spark and Spark is optimized to work on many small files, you might find it odd that you have to get your sources into a file format before you see Databricks shine. The good news is Databricks has partnered with several different data ingestion solutions to ease loading source data into your data lake.

It is interesting to note that Azure Data Factory was on this list until earlier in 2022. You can still use it to move data from your sources into your data lake. The difference is now, Databricks no longer cross-promotes ADF. In most of my deployments to Databricks in Azure, we still use ADF. The one notable exception is some companies picking up Fivetran to automate their data ingestion.
Fivetran is ETLaaS
Fivetran has built a business around building ETL pipelines for their customers. They’ve even developed a simple user interface to control the process. Customers sign up for the service, click on the service they want to ingest, fill in a few details, and are up and running. Fivetran takes the cost of maintaining the ETL code. You, the customer, pay for what you use as you use it!
You don’t have to struggle with full vs. incremental load logic.
That means you don’t have to fix anything when your salesforce API updates. Fivetran does it.
You don’t have to build auditing and logging; that’s built into the service!
Fivetran is the closest version to ETLaaS I’ve found. You can get a free trial and give it a try. It’s pretty impressive.
ADF to Ingest Source Data
If you’ve already invested in ADF and built an ingestion framework, stay with it. Updating your current framework to work with Databricks is a breeze. All you have to do is define a linked service for your Azure Data Lakes Storage account and then use that linked service as your destination. I highly suggest any training materials Andy Leonard has published if you need tutorials on getting started with ADF.
Some Data Lake Terminology
This source data you’ve landed in your data lake can be referred to as your “raw” or “bronze” zone. The only transformation you should have performed on this raw data is a transformation of storage medium. For example, the source could be SQL Server. You want to read that data into CSV, JSON, or Parquet format. You don’t want to introduce changes to the source data, such as reformatting dates or merging this source data with another data set (for example, adding a lookup value).
When ready to transform your source data, you will write a copy of that transformed data to your “silver” zone. In silver, you could have aggregations, lookups, merges, etc. This is where your conformed data lives. This zone is most similar to operational data stores in database terms. You could model this layer using a DataVault approach if you desire.
Silver data normally is never directly consumed by end users or BI tools.
When you’re ready to publish data to end users, you will land a separate copy in your “gold” zone. This three-zone paradigm is the most common approach in Databricks solutions.
Orchestrating Bronze to Silver to Gold
Once you have landed your source data in bronze, you no longer want to pull that data out again to transform it. You’re now in an ELT mindset. Fortunately, Databricks supports many approaches to transforming the data in your data lake. You can use Databricks-SQL, Python, or scala to perform these transformations. Use the one that works best for you and your team.
I want to introduce you to a few tools built into Databricks that can make this process easier than building it all from scratch. Auto Loader is a tool that can keep track of what data has moved past a certain processing point. That way, it manages what data should be included in your incremental loads! You no longer have to maintain watermarks and timestamps to handle incremental loads.
Delta Live tables (DLT) can allow you to write tiny code snippets and still get fully-featured data pipelines. DLT gives you automatic data quality checks, schema evolution, and monitoring with very little code.
Take these two and combine them with a metadata-driven approach, and you can roll from bronze to Gold with very little effort!
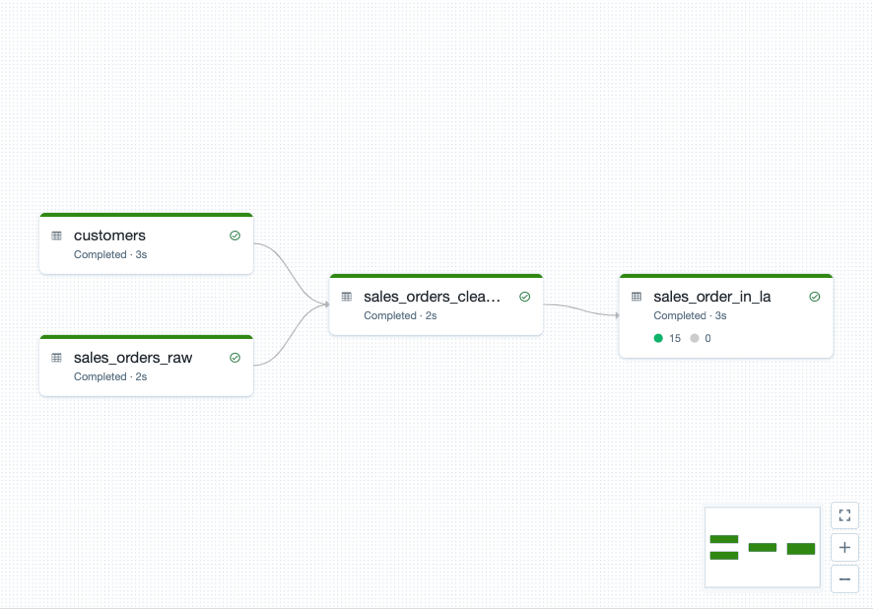
When it comes time to orchestrate your steps, you can define dependencies programmatically or use visual workflows.
Conclusion
Data engineering in Databricks is a vast topic. After getting through the blog entries for this overview, I plan to come back and dig deeper into these details. I’m also planning on sharing what a metadata-driven approach could look like as you move from traditional databases to a broader world.
Next time, I’ll continue the introductory series by showing what Databricks looks like for the BI Developer. Until then, if you have any questions, please send them in!
Hi Shannon
is it you commented on my blog post about DLT unit testing? If yes, can you drop me an email? Or maybe better start a discussion on github. For some reason I can’t answer to your comment on blogger 🙁
I’ll reach out by email shortly.