
Last time, we walked through how to perform analysis on Databricks using Visual Studio Code (VSC). This time, we will set up a local solution in VSC that will let us build out our data engineering solutions locally. That way, we don’t have to pay for development and testing time. We’d only pay for Databricks, compute, and storage costs when we deploy our solutions!
Install and Configure Python
Before getting started, you will need to install Python on your local development machine. Depending on your cluster’s version of Databricks, you’ll need one of three versions of Python. If you’re running 11.0 or newer, install Python version 3.9.5. If you’re running 9.1 LTS to 10.4 LTS, you’ll install 3.8.10. If you’re running a version older than that, you’ll want 3.7.5.
Once you have a version installed on your machine, ensure you include the path to your install folder in your PATH variable. That way, you’ll be able to execute the command without needing to type out the full path each time.
Also, if you’re using Windows 11 on your development machine, you will need to disable the Application Execution Aliases for Python. Microsoft thinks that when you type in Python, you want to go to the windows store. To disable this “Feature,” simply open Settings -> “App execution aliases” and disable the two for Python.
You’ll also want to Install pipenv. This allows you to run multiple virtual python environments. This will enable you to set up multiple unique python solutions on your machine without having them break each other. Install is easy; open a command prompt to your local development folder, and run the following command.
pip install pipenvFinally, you’ll want to add the Python extension to VSC. This adds many features we’ll use in developing our Python-based data engineering workloads. Open your Extensions panel, type in Python, and install.

While installing extensions, install Python Test Explorer for Visual Studio Code. We’ll need it when we start building tests for our data engineering solution.
Set Up Your VSC Workspace
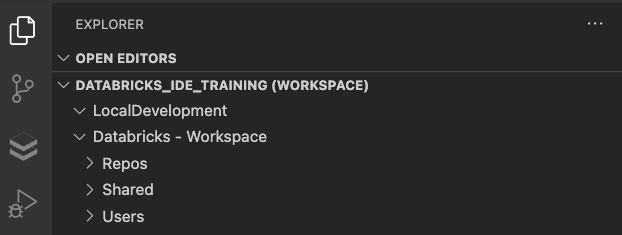
In the last entry, we added our Databricks Workspace to our VSC workspace. This time we will add a new local folder to our workspace. This can be a repository folder, or it can be a standalone folder. I do encourage you to get used to working in repositories. You get all the version control features and one of the most accessible deployment options for Databricks missing with a standalone folder.
To add another folder to our VSC workspace, click File -> Add Folder to Workspace. Create a new folder, or choose an existing folder to add to your workspace. Now you should see something like the following in your Explorer view.
Configure Your Virtual Python Environment
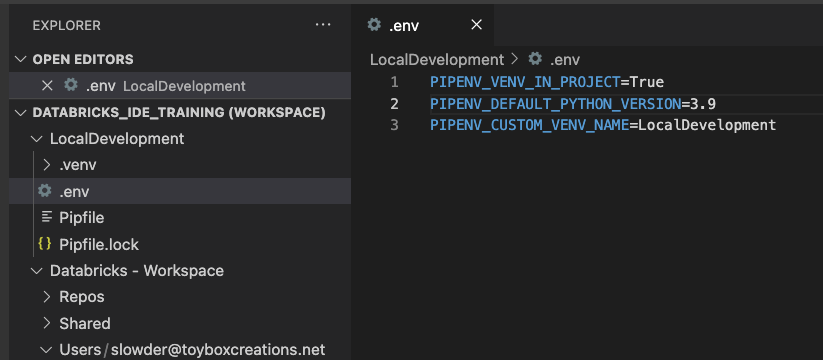
I like configuring my virtual environments, so they’re stored in my project folder. That way, they’re easier to manage. To do that, I add a .env file to my project folder. I would also check this file into source control when using a repository folder. My .env file follows the following template.
PIPENV_VENV_IN_PROJECT=True
PIPENV_DEFAULT_PYTHON_VERSION=<full three dot version number>
PIPENV_CUSTOM_VENV_NAME=<project name>So, for this demo, my env file contains the following:
With this file in our folder, we can open a terminal to our project folder, run the following command, and our virtual environment will be created.
pipenv installYou’ll see something like the following scroll by.
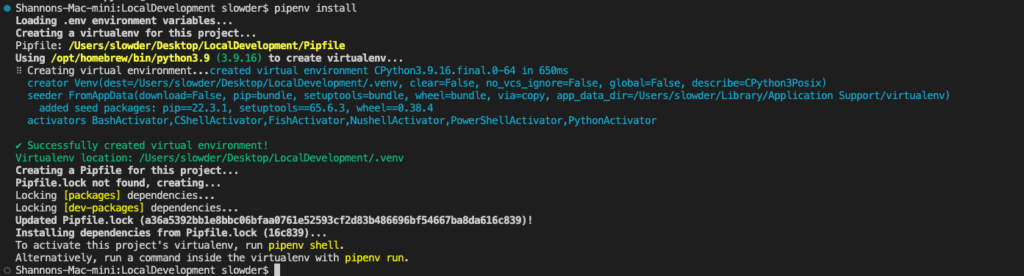
And when that completes, you should notice a new folder named .venv, a file named Pipfile, and Pipfile.lock have been added to your local development folder.

Add Packages to Your Virtual Environment
Depending on what your data engineering solution needs to do, you’ll want to add packages to your virtual environment to make that work possible. There are two ways you can do this. You can run a pipenv install command for each package you want to install, or you can create a requirements.txt and install all your requirements at once.
There’s one package I use on every Databricks solution, pySpark. Installing this package is key to developing my solutions offline. You’ll want to install the same version of spark your cluster is running. Currently, 3.3.0 is the version Databricks 11.3 LTS runs.
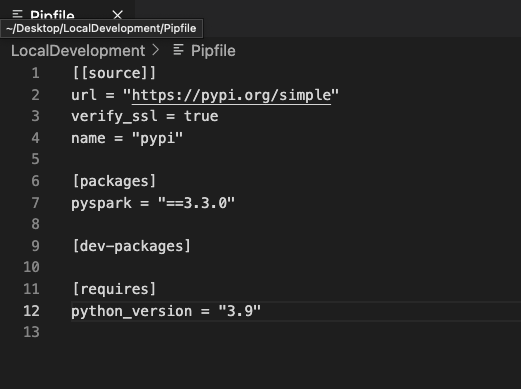
pipenv install pyspark==3.3.0If you open the Pipfile in your solution, you’ll notice that the package is now listed in your [packages] section.
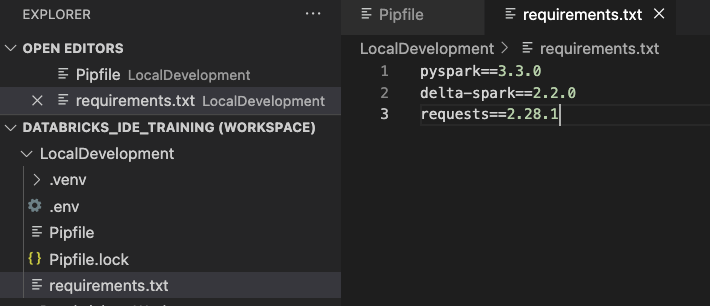
If you require many packages for your solution, you can use a requirements.txt file to install them all at once. In my case, I want to install pyspark, delta-spark, and requests for my solution. So I add the following to my requirements.txt file:
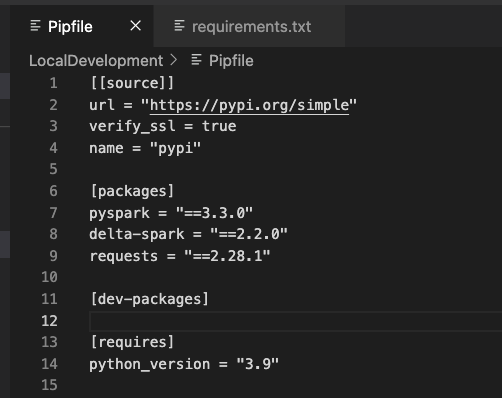
Then run the following command from my local development folder.
pipenv install -r requirements.txtYou’ll then find your Pipfile has been updated once more.
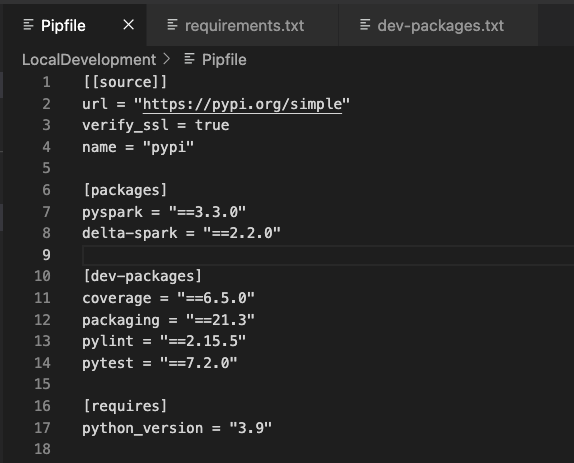
Later in this demo, we’ll explore linting, testing, code coverage, and deployment. Let’s go ahead and set up some dev-packages to help us with this development work. Create another file in your local development folder named dev-packages.txt and add the following packages.
coverage
packaging
pylint
pytest
setuptools
wheelThen run the following command to install those packages to our dev-packages section of our Pipfile.
pipenv install --dev -r dev-packages.txtYour PIpfile should now look like this.
Conclusion
You’re now ready to start developing your data engineering solutions locally. If you need a hand getting set up, let me know! Double-check that you have Python in your PATH variable if you get any errors while following this guide. Most of the time, messing that up will prevent the rest of this guide from working.
In the next entry, we’ll build a simple ingestion example. This will include unit tests to illustrate how we can build more reliable data engineering solutions. All that before paying a single cent for compute!