

When we start developing in a new language or on a new platform, it’s easy to fall into the trap of monolithic design. The free flow from idea to code leads to a single blob of functional code. This leads to quick prototype code that meets the functional requirements.
The problem with this approach creeps in slowly. You might demo the code a few days later and discover an exception that wasn’t there originally. This leads you to add in one or more error handlers. Your code now reads a little less fluid than it did before.
After this one test, you might want to start running it on a schedule as a job. So you adjust the code again so that it will run as a service principal. The code is slowly growing away from that simple prototype.
After deployment, one of the first steps your code takes in its process changes; you now have to make more changes to handle that case rather than just touching the single step. By touching the whole code base, you can’t test your change. You have to test all the code or none of it.
You finally make it through that change and redeploy the code. Sometime later, another code step takes far longer to complete. Since you have a single code base, you can’t scale that one step separately, so you have to scale up the whole process.
After a while, the problems become too great.
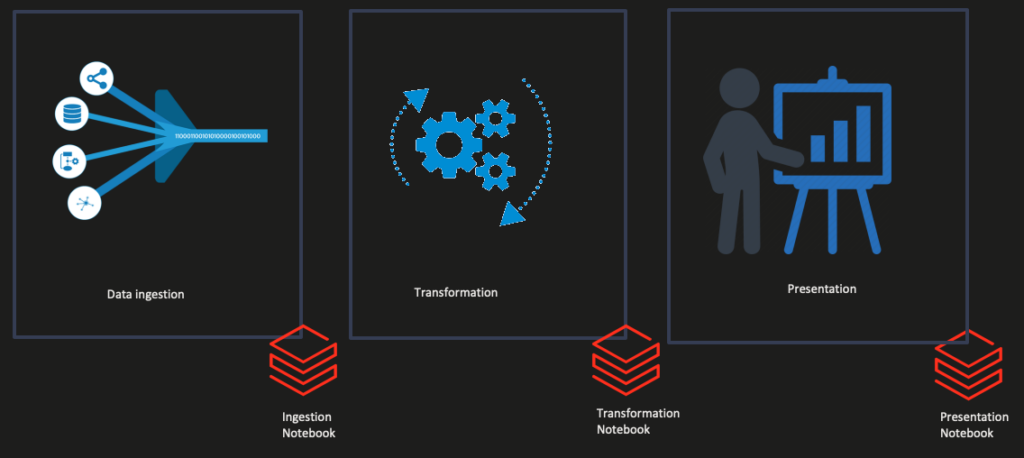
By breaking the code into separate functional steps, you can avoid these problems.
Building these smaller, independent, reusable components creates easier-to-maintain code. These smaller components have a single function, becoming more accessible to understand than the delicate interdependency in monolithic designs. These smaller components also allow you to become more agile in your development strategy since you can sashimi an extensive multi-step process into their steps to assign during the sprint.
Each change can be tested separately from the rest of the process. This allows you to make code changes as you learn more about how your data engine works or as new technologies come along. As long as you have a given input and output contract for what each notebook handles, other notebooks won’t care if the internals of a given notebook change. This enables greater growth in your development team in the long run, as you’re not locked in how a step must run not to break the whole process.
You can also re-use code more efficiently by adopting strategies like metadata-driven design. Each component deployed can be scaled separately from the others. Again, a notebook’s internals are free to change when adopting the unit-of-work approach. This allows for more elegant code to be designed, code that can handle more variation, yet only handle a single unit of work.
If a single step becomes slow-running, you can scale it independently from the other steps. You can deploy multiple job clusters, some for small quick processes and others for more significant and long-running processes. You could even go so far as to deploy clusters dynamically as performance changes over time. The only requirement is an orchestration system that handles the ordering and dependencies between steps.
In the end, breaking the easygoing nature of monolithic design into more structured unit-of-work notebooks produces higher-quality solutions. That higher quality builds trust in the technology and team developing those solutions.