Recently I was asked to look into Delta Sharing to learn what it’s all about and how it could be used. fter digging in a little bit, It appears that it’s a way to share data in parquet or Delta format. ou can build these shares on top of any modern cloud storage system like ADLS, S3, or GCS. nce you’ve set up your Delta Sharing server (or service if you’re using Databricks), you can even share this data outside of your organization!
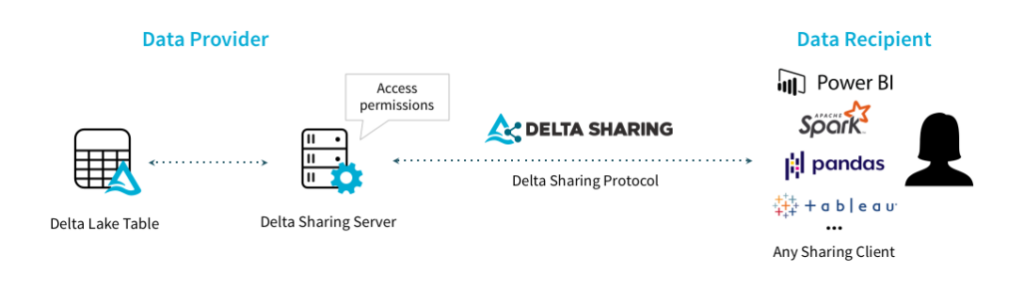
Through Delta Sharing, you can control who has access, and if you build your share on top of a Delta format source, you can even control which version of the data the user gets access to. his can be helpful in cases where data providers may want to release scheduled updates to the data. or example, you want to release monthly data feeds and don’t want to risk data getting out too early.
Let’s connect to an existing Delta Share with a few different clients.
Spark or Pandas Consumer
To get started with this first demo, you’ll want to install the delta-sharing package into your python environment. fter that, you’ll need a profile for the share you wish to access. n this case, I’m using the example share provided by delta.io. tore this file in a location your python code can access.
import delta_sharing
# Point to the profile file. It can be a file on the local file system or a file on a remote storage.
profile_file = "open-datasets.share"
# Create a SharingClient.
client = delta_sharing.SharingClient(profile_file)
# List all shared tables.
client.list_all_tables()
The delta-sharing package has two functions you’ll be interested in. he first is load_as_spark. his one can only load the entire table. e careful unless you have enough memory to load the whole table into your spark executors’ memory (or have caching set up).
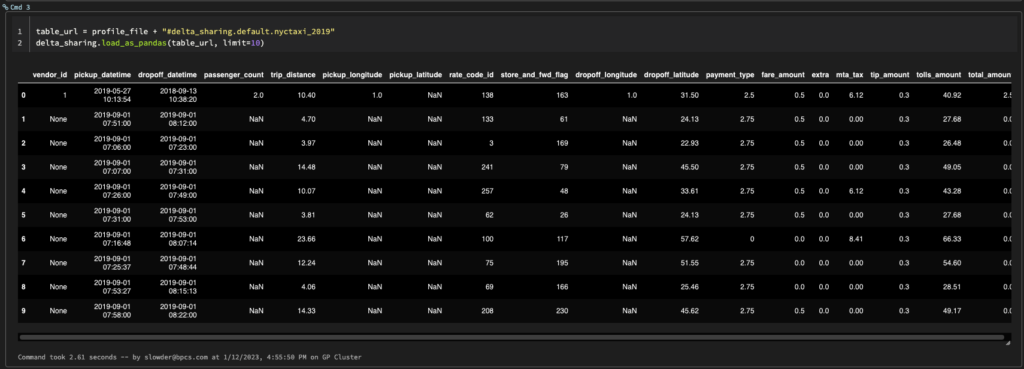
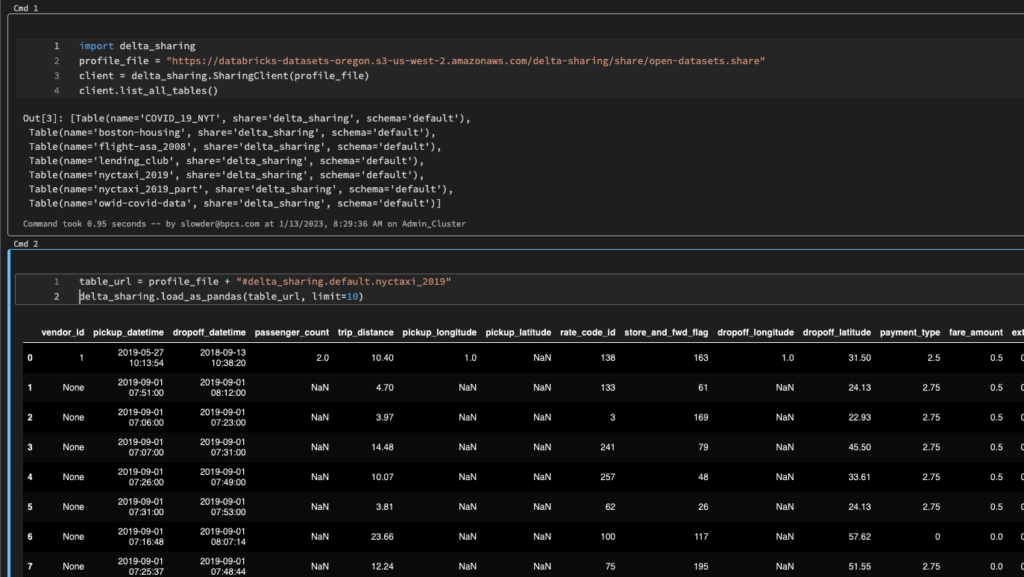
table_url = profile_file + "#delta_sharing.default.nyctaxi_2019"
# If the code is running with PySpark, you can use `load_as_spark` to load the table as a Spark DataFrame.
delta_sharing.load_as_spark(table_url)Fortunately, there is a load_as_pandas function. t has an optional second parameter, limit. sing that, you can limit the number of rows loaded.
# load_as_pandas can also be used to load a subset of the data.
delta_sharing.load_as_pandas(table_url, limit=10)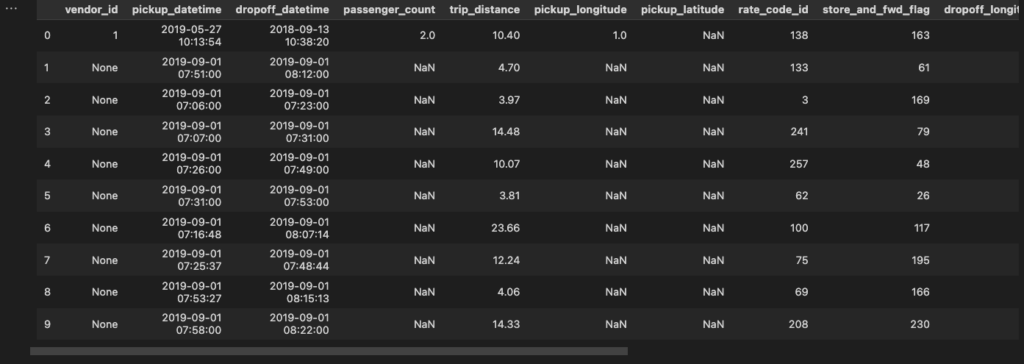
Databricks Consumer
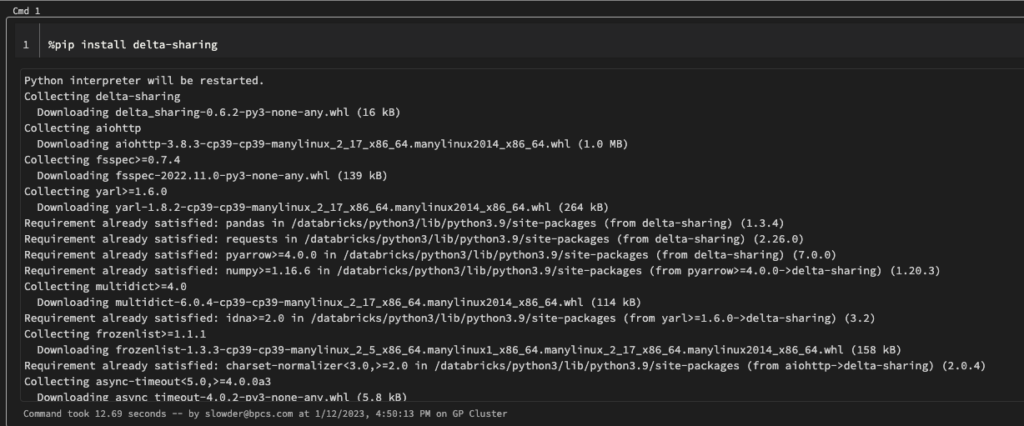
here are two ways to install and consume the package. You can use the delta-sharing package in Databricks. ou could pip-install it through a notebook. he downside is that you’ll have to wait for the package to install each time you run that notebook. ou could also install the package to clusters and have access to it each time those clusters startup.
Installing through a notebook
Start with pip install. N ice it takes 12 seconds to download and install the package from PyPI.
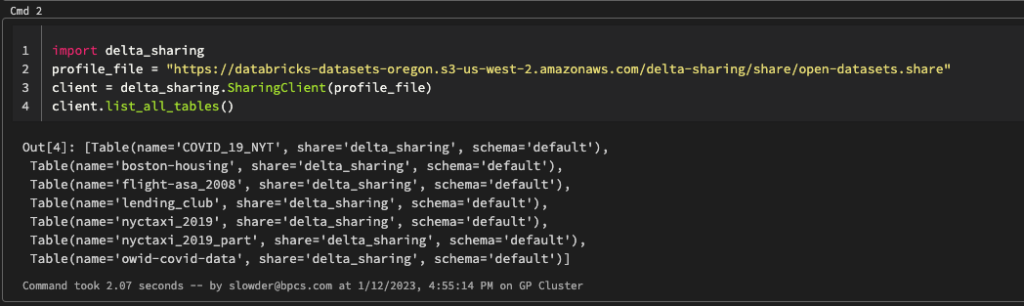
Then you can run the same commands we did in our previous example.
Installing on Clusters
Now that our library is installed in the workspace, we can install it on our clusters. C ck compute on the left bar, then choose any cluster you want to install delta-sharing. Wa ning, you cannot install libraries on shared clusters that use Unity Catalog.
On the next page, click Libraries and then Install new.
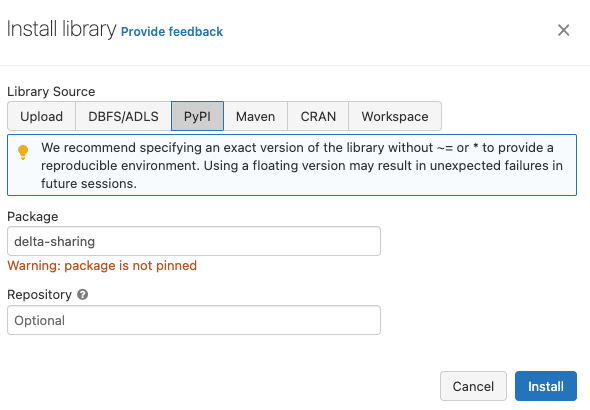
You can click PyPi and then type in delta-sharing. Y will notice the warning to select a version number to ensure a more stable development environment. I this case, I’m just installing the latest, 0.6.2. Cl ck Install to continue.
It looks like Databricks has removed the option to install libraries automatically on all clusters, so you have to install the delta-sharing onto each cluster you want to use it on. Now that we’ve installed the library, we can restart that cluster and run our demo from before. This time we can skip the pip install step.
PowerBi Consumer
For the PowerBi demo, we’ll use the desktop experience. I’m running the December 2022 update, version 2.112.1161.0 64 bit. You should find delta sharing features in the web version as well. The details PowerBI will need are found inside the .share file. Open your share file so you can copy and paste the details.
{
"shareCredentialsVersion": 1,
"endpoint": "https://sharing.delta.io/delta-sharing/",
"bearerToken": "faaie590d541265bcab1f2de9813274bf233"
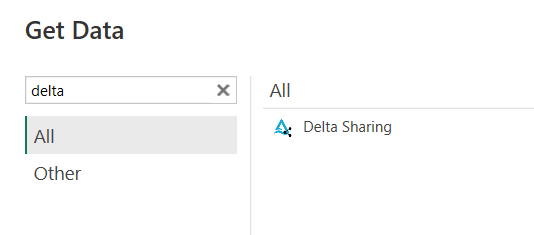
}Create a new PowerBI file, then click Get Data on the top bar. Type “delta” into the search bar.
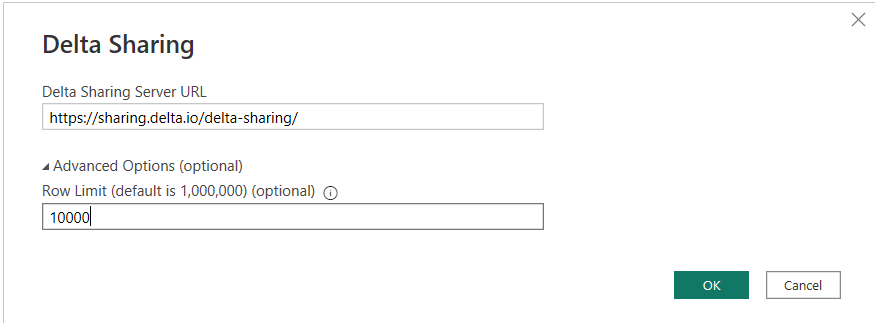
Click Connect to continue. On the next screen, enter the endpoint from your share file into the Delta Sharing Server URL. Under advanced options, you could limit the number of rows returned. This limit would apply to all tables in the share. I’m going to limit mine to 10,000 rows. Click OK to continue.
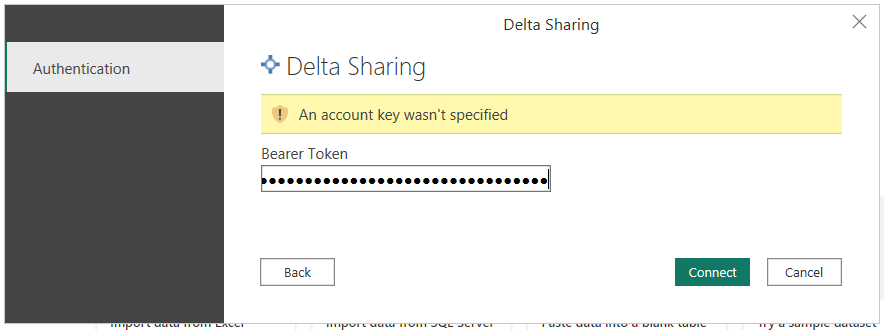
Next, you’re prompted for a bearer token. Copy that from the share file and paste it into the prompt. Then click Connect.
On the next screen you can explore the share. You’ll see all the schemas and tables shared. Select all the tables you’re interested in and then hit load. If you get an error telling you ParquetSharp is missing, You need to completely uninstall and reinstall the December 2022 or later version of PowerBI. It’s a known bug.
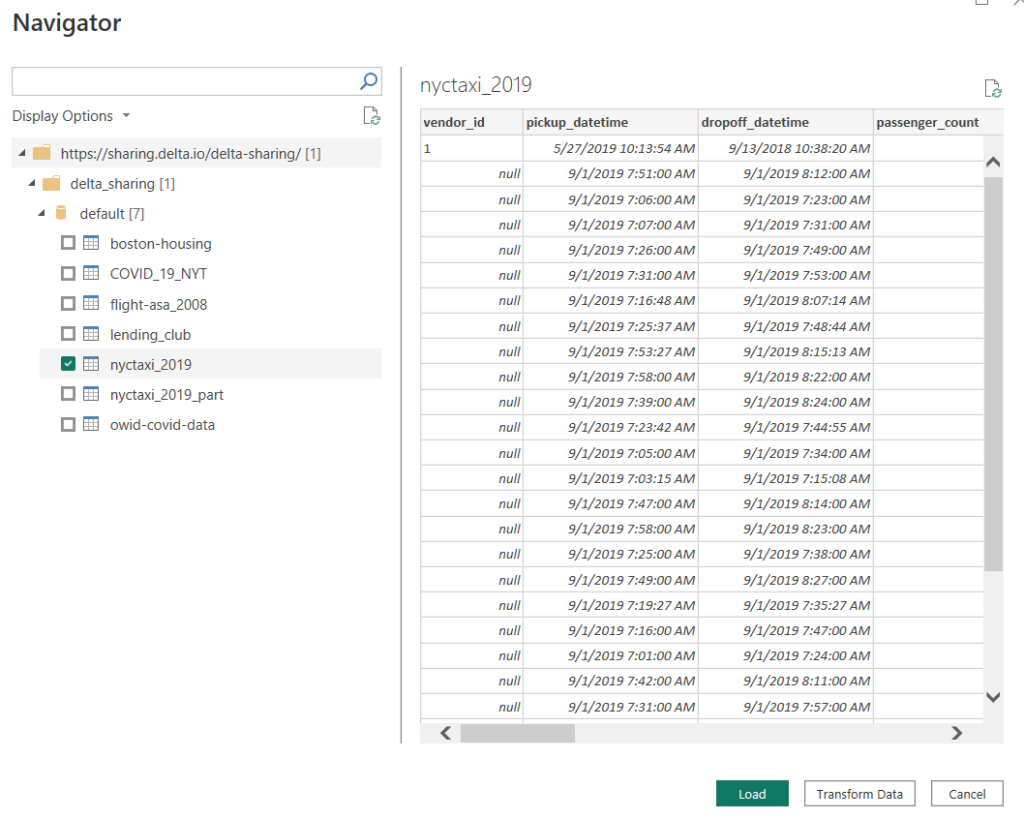
Now you can use the delta sharing data in your visuals.
Conclusion
It’s pretty easy to get started with Delta Sharing as a recipient. Everything you need is provided in a .share file. Many clients can read that share file, others will require you to copy the URL and bearer token into the client before it will connect. Next time, we’ll work through setting up a share server using Databricks as the host.
In the meantime, if you have any questions, let me know.