As I mentioned in the overview, the largest cost in terms of time is the requesting each web page from the web server and downloading that file to disc. That’s why this file staging loop is a separate step from the parsing and transforming step. This loop can be as simple as two steps: get a list of URLs to process and process that list. If you don’t plan for problems, and plan for reprocessing, you’re in for a lot of pain. Let’s dig into these two steps and see how we can plan out our staging loop a little more completely.
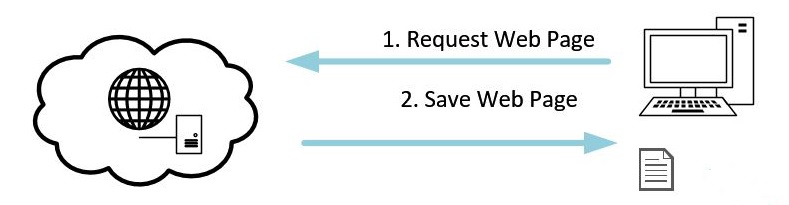
Get a List of URLs to Process
If you’re lucky, the URLs you’re looking for will have an easily recognizable pattern to them.
- http://sourceServer.com/data/?recordID=1
- http://sourceServer.com/data/?recordID=2
- http://sourceServer.com/data/?recordID=3
If your source pages are formatted this way, all you have to do is come up with a way of determining the first and last for your series. There will be one other problem when you start processing. How do you handle the case where one of your URLs in your series has no data, or can’t be found on the server (Error 404)? We’ll address that in a future article. Determining the first URL in the series is usually the easy problem to solve. When you hit your source, often the first URL appears on the first page of results. All you have to do is make a note to yourself: this is the first URL. Finding the last is a little harder.
Many times, I’ll do a “blank search”. From the source server type nothing into the search box, and hit go. You’ll get a list of results, along with a list of how many pages in your results. From there, I simply click on the last page over and over until I truly get to the last record. Then make a note: this is the last URL. After learning to use HTMLAgilityPack (HAP), you could automate this process, and when records are added, simply add them to your list of URLs to process.
Another alternative is to simply guess at the last record. Take the example above for sourceServer.com. Let’s guess the last record is 50,000. Simply try to hit that URL: http://sourceServer.com/data/?recordID=50000. If you don’t get a 404 error, try again. You could also automate this guess as well. The problem is, what if 50000 isn’t defined, but 50001 is? Using this kind of guess will take several tries to figure out the true maximum URL. You’ll also have to determine how many sequential 404 errors, before processing gives up.
 The alternative to guessing is the same method I use when URLs cannot be predicted. I start with a search. I’ll try to type nothing into the search box, then hit go. This won’t always work. Sometimes, the site will have a minimum length on the search terms. In those cases I try to search on terms that will return tons of results. Think about searching for “a”, “an”, “and”, “the”, or “of”. Get creative here. You’re looking for ways to perform searches to get as many URLs with the fewest searches.
The alternative to guessing is the same method I use when URLs cannot be predicted. I start with a search. I’ll try to type nothing into the search box, then hit go. This won’t always work. Sometimes, the site will have a minimum length on the search terms. In those cases I try to search on terms that will return tons of results. Think about searching for “a”, “an”, “and”, “the”, or “of”. Get creative here. You’re looking for ways to perform searches to get as many URLs with the fewest searches.
Once you have your search(es) that get all the URLs, look at the results page. Most of them will give you some key pieces of information. Look for a number of results. If you see that the source server in question has 12,450 results for a blank search, you know how many URLs you expect to find. If you don’t get a number of results, you may find text stating “Showing results 1 – 25”. You now know how many results per page. So far every site I’ve sourced from will show a page navigation bar at the top, bottom, or both sides of a results page. It may not show how many pages total, but there is always a way to go to the next page. You could manually page through, or you can use HTMLAgilityPack to find that next page button, and traverse each page automatically.
Let’s say you have the worst case scenario, where you have to get a list of URLs that represent the pages of results, and then you need to search each of those URLs for a list of URLs for your records. In this case, you’ll have two staging steps. The first staging step will simply look for pages to pass on to the next step. The second will process URLs and save those to local disc.
How Do I Find URLs in a Page?
If you’re using Chrome, hit F12 to open developer tools. What you’ll see on the right side of your screen is the HTML that created the page you see on the left. If you’re not using Chrome, lookup how to “view code” from your browser. Most often this is Ctrl+U. The reason I like the dev tools in Chrome is I can explore the HTML. As I open nodes in the code, I can see what section of the page is created from that code. I’ll explore the code until I find the node that has the data I’m looking for. In this case, I’m looking for URLs to process.
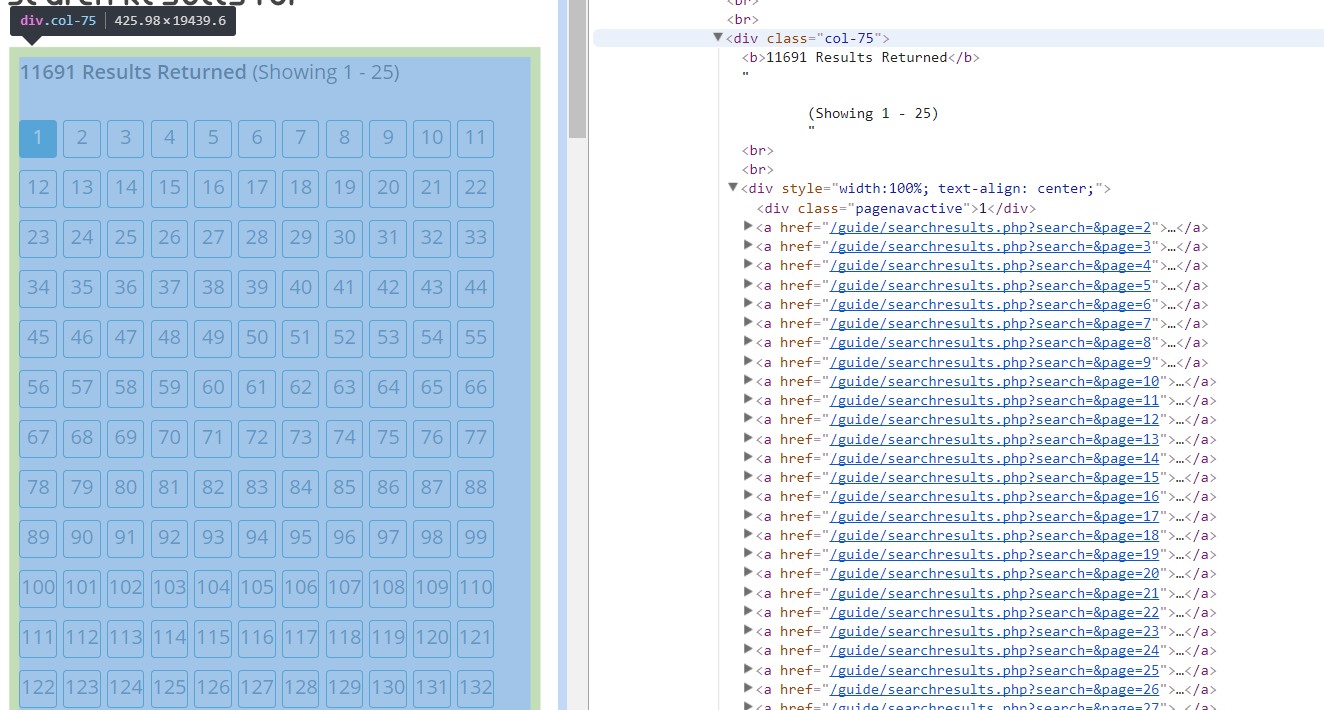
In this case I see the URL for each page in my search results are listed in this one div with the class “col-75”. Let’s take a look at that div as a HTML node using HTMLAgilityPack. I’m going to use LinqPad, I really enjoy how it represents objects on screen by using Console.WriteLine. For this demo code I have already added a reference to HTMLAgilityPack.
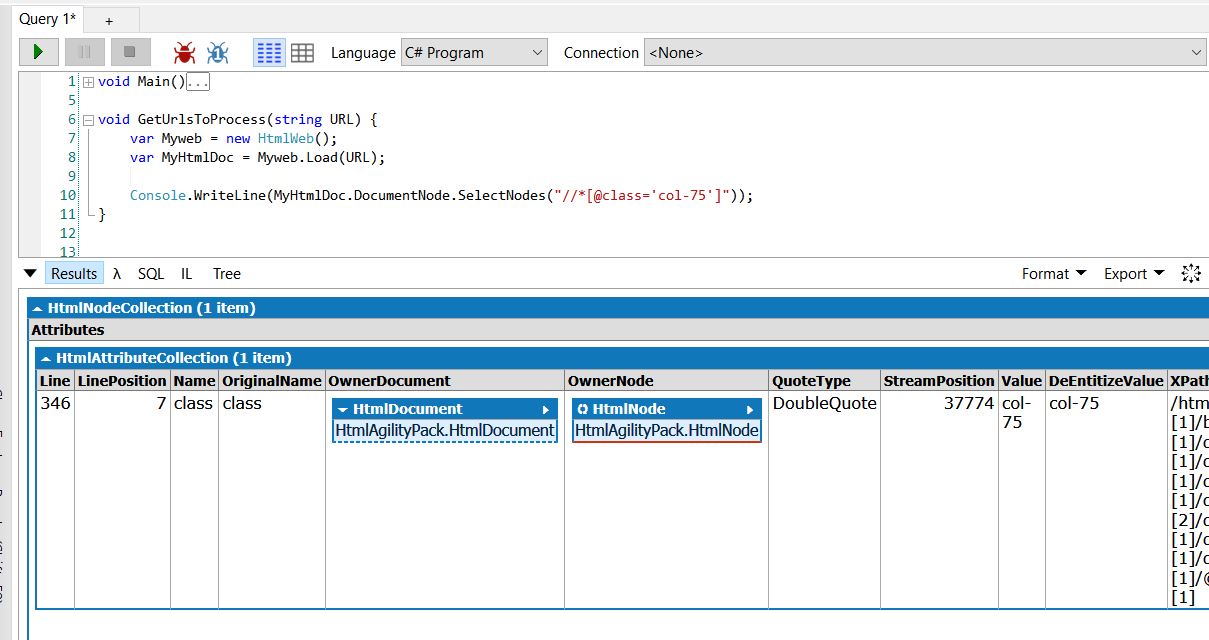
My function is simple at this point, I instantiate the HAP utility class for getting an HTML file from a URL, and then I use that class to load a URL into a HAP object that I can then work with to get data out of the web page. Once the page is loaded into MyHtmlDoc, I want to look at the document itself, and get any nodes that are using the class “col-75”. If there’s more than one, then I’d have to do extra processing with Linq to get the “right” one. Fortunately, there’s only one.
So now that we have the right node, we need a way to spin through all those links we see in the HTML code we saw earlier. We can use Linq to spin through them for us!
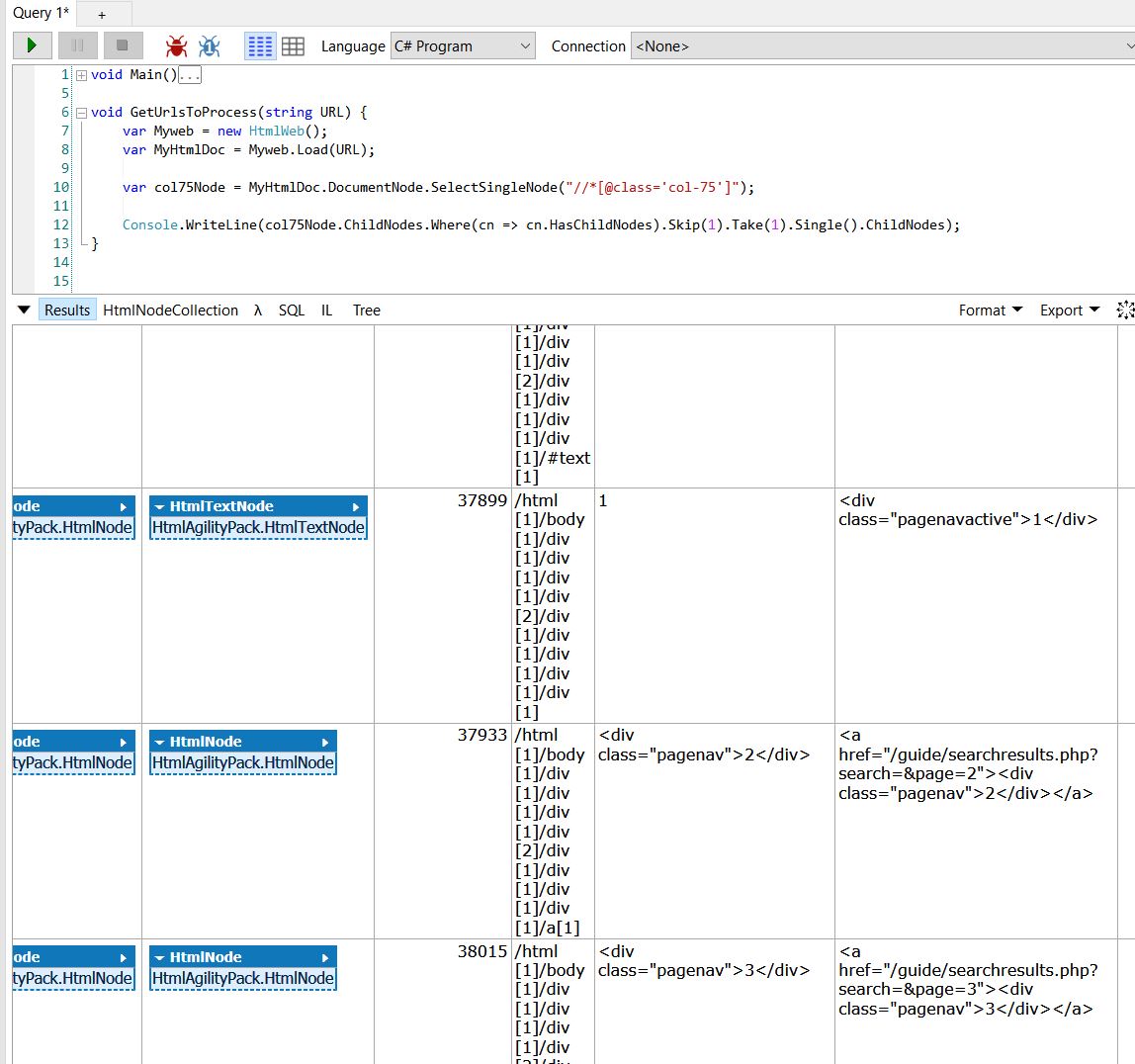
Notice I stored the col-75 node in a variable on line 10. The links we’re looking for are children of this node. So on line 12, you see I’m writing col75Node.ChildNodes out to the screen. What you will find when you only use that part of the code, there are other children nodes in the col-75 node. So first, I ask for only those children nodes in col-75 who have their own children. That’s what I mean by col75Node.ChildNodes.Where(cn =>cn.HasChildNodes).
Where is a Linq function you can think of just as you would a where clause in SQL. In Linq, you can create these transient functions that define the test you want to perform. These transient functions are called lambda expressions. the lambda expression accepts only one parameter, and that’s whatever the object is right before the Linq function. So in this case, the parameter for my where clause will be each one of the children nodes under the col-75 node.
Each of these children nodes have an attribute HasChildNodes. It’s true when the node has children nodes, and false when it doesn’t. Since I only want those with children, I pass in cn.HasChildNodes. That code is the same as writing cn.HasChildNodes == 1.
When we look at the children nodes in col-75, where they do have children we notice the first result doesn’t have links, it’s just a summary of how many results there are. We didn’t get a built in version of skip and take in SQL server until 2012. In SQL it’s referred to as OFFSET X ROWS and FETCH NEXT x ROWS. In C#, Skip(x) does exactly that, it skips over x rows in your result set. Take(x), is like a TOP statement in SQL, it returns only x rows. In this case, if we skip the first result (the one with the number of results), then the very next node is the one that has all the links we want to process. That’s what I mean by the code: col75Node.ChildNodes.Where(cn => cn.HasChildNodes).Skip(1).Take(1).
Now, you and I both know that I just want one node back, right?
Just one problem: Linq doesn’t know that. Linq assumes that it’s dealing with collections of objects instead. That’s where Single() comes in. It’s a Linq function that takes your single object out of the collection so you can deal with it as a single object. This is important because a collection of children nodes cannot contain children nodes, but a single child node can have a child node.
And that’s what I get by the full code: col75Node.ChildNodes.Where(cn => cn.HasChildNodes).Skip(1).Take(1).Single().ChildNodes. You’ll see that i have a collection of nodes that have links to the URLs I’m looking for. I do have to scrape out the contents of the links, but that’s simple now that I have the list of links.
Next Time
That was a lot of explanation! Take plenty of time to review these concepts and try them out for yourself. Next time, we’re going to work through how to log these URLs to a table so we can process them. In that article we’re going to start adding in parallel processing, an important concept if you want to get the data in a timely manner. In the mean time, if you have any questions, please feel free to hit me up! I’m here to help.