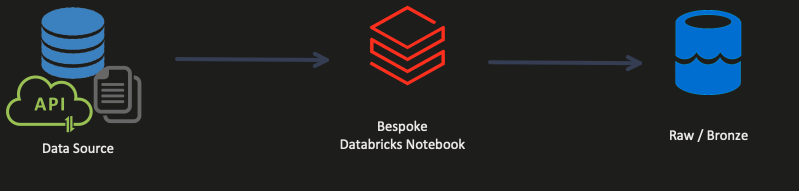
You will manually build your ingestion code when you first learn to ingest data into any new engine. This makes sense; you’re just getting started. You want to learn how the engine will read the data and then write it back again. You want to learn how to log what’s happening during ingestion. You want to learn how to track lineage within the engine. You want to learn to handle errors as they occur.
But there comes a time when you’ve learned all these concepts for the new engine, and you’re ready to evolve. Now, it’s time to look at a metadata-driven approach.
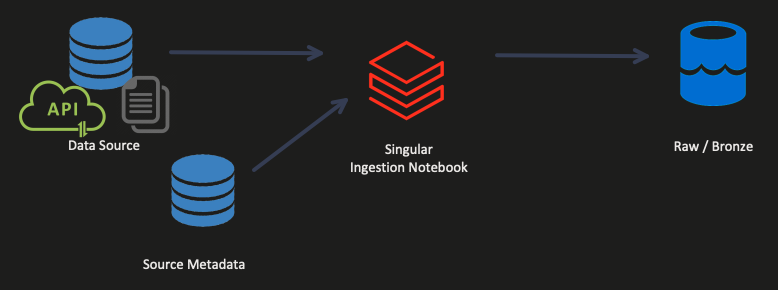
Once you’ve written several dozen ingestion patterns, you will notice they’re all remarkably similar. You define where the data is coming from, where the data should be written, and how that data should be written. These are the simplest three pieces of metadata you can use to drive your ingestion process.
Your auditing, logging, and lineage functionality will be configurable, but you want it to be standard across all your ingestion. That way, you can gain insight from ingestion runs.
As you start building out your singular ingestion notebook, you may want to handle specific sources differently than others. For example, you may have files that land in one folder in CSV format, and you want those automatically moved to your Bronze layer in Parquet format. At the same time, you may have API sources that require authentication, paging, or other features to work. Build more complex libraries to support your singular ingestion entry notebook. So long as all of the functions work together consistently, following your required business logic, you succeed.
Adopting this strategy allows you to adopt a single set of tests for all ingestion work moving forward. You may add tests to this suite as you discover additional ingestion functionality needs. Still, it will be a single point to test, manage, and deploy across your entire Databricks estate.
This same pattern can be adapted for transformations where you can easily describe your data’s source, transformed state, and destination. This same pattern can apply.
Demo
In a recent project, I found that the code to ingest data from an API was written multiple times, once for each endpoint. The problem with this approach is when you need to change the authentication method or some other common feature, you would have to make that change in multiple places. The solution is to build a single method that reads the data into a data frame and reference that method instead.
I’ve built a demo that uses the NHL API to simulate the original code. The original code is intended to ingest all data from an API’s endpoints. The code was repeated several times, only changing the URL and the resulting data’s parent attribute name.
import json
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
import requests
builder = SparkSession.builder.appName("originalDemo")
spark = SparkSession.builder.getOrCreate()
sc = spark.sparkContext
#ingest team data
url="https://statsapi.web.nhl.com/api/v1/teams"
response = requests.get(url).json()
result_json = json.dumps(response["teams"])
df = spark.read.json(sc.parallelize([result_json]))
df.show()
#then write it to disk
#ingest the division data
url="https://statsapi.web.nhl.com/api/v1/divisions"
response = requests.get(url).json()
result_json = json.dumps(response["divisions"])
df = spark.read.json(sc.parallelize([result_json]))
df.show()
#then write it to disk
... several more endpoints, and then finally
#ingest player data (in a loop)
url="https://statsapi.web.nhl.com/api/v1/people/8480830"
response = requests.get(url).json()
result_json = json.dumps(response["people"])
df = spark.read.json(sc.parallelize([result_json]))
df.show()
#then write to disk
The code could be significantly simplified. The only metadata needed in this example is the URL and result name. We could replace all of the above with two functions. I write my solution as classes; that’s why you’ll see self as the first parameter for each function. The first gets JSON data from an API endpoint.
def get_json_from_endpoint(self, url, timeout = 60):
"""
This method gets the JSON data from the API.
Parameters:
url (str): This is the url to the API endpoint.
timeout (int): This is the timeout for the API call.
"""
try:
response = requests.get(url, timeout=timeout)
return response.json()
except requests.exceptions.HTTPError as request_error:
print(request_error)
return NoneBy making this a separate function, when we need a version of this code that supports Authentication options, we can come here to add it! Next, we add a function that takes that JSON and returns the result attribute as a data frame.
def get_nhl_results_dataframe(self, input_json, result_name):
"""
The NHL API returns a dictionary of copyright and <results> for each endpoint.
This method will get the results from the JSON data as a dataframe.
Parameters:
input_json (dict): This is the JSON data
result_name (str): This is the name of the results key in the JSON data.
"""
if not result_name in input_json.keys():
print(f"The JSON data does not contain {result_name}.")
return None
result_json = json.dumps(input_json[result_name])
return self._spark.read.json(self._sc.parallelize([result_json]))Now that we have two functions, we could spin through any number of endpoints by using a simple collection of URLs and result names.
Conclusion
Moving from manually built to metadata-driven code can seem complicated when you’re getting started. But the skill is worth learning. This approach can set you up with a single code base that reads in nearly any format and lands it neatly in your Bronze (raw) zone. You can even use this approach to build a catalog of transforms that can handle any source and destination you want.
If you have any questions, let me know!