As a professional, I place a high value on my role as a data engineer, with consulting being a close second. My role requires both technical and interpersonal skills. I’ve come to depend on two AI-based tools to enhance both. Grammarly has helped me be cognizant of my tone and style of writing. Copilot has allowed me to be more productive in languages I have less experience with.
Grammarly
I started using Grammarly Premium back in 2016 after using the free version for a few years. At first, I used it to help keep my spelling and grammar in check. The tool kept growing. Through add-ins to my browser, Office tools, and later a desktop client, I could use the tool everywhere, from statements of work to my instant messages. Soon they could help me recognize when I was using a passive voice. The software helped coach me to write more convincingly. As ChatGPT and the like came around, Grammarly added even more tools to help me fine-tune the tone of my messages.
Grammarly has unveiled a new feature called GrammarlyGO, which utilizes generative AI to enhance your writing. With this tool, you can outline your ideas and include your key arguments, and AI will fill in the gaps. The feature also offers several options to optimize the AI’s output and improve the quality of your writing.
For example, The paragraph above was a rewrite suggested by the bot. You can see my original paragraph highlighted below.
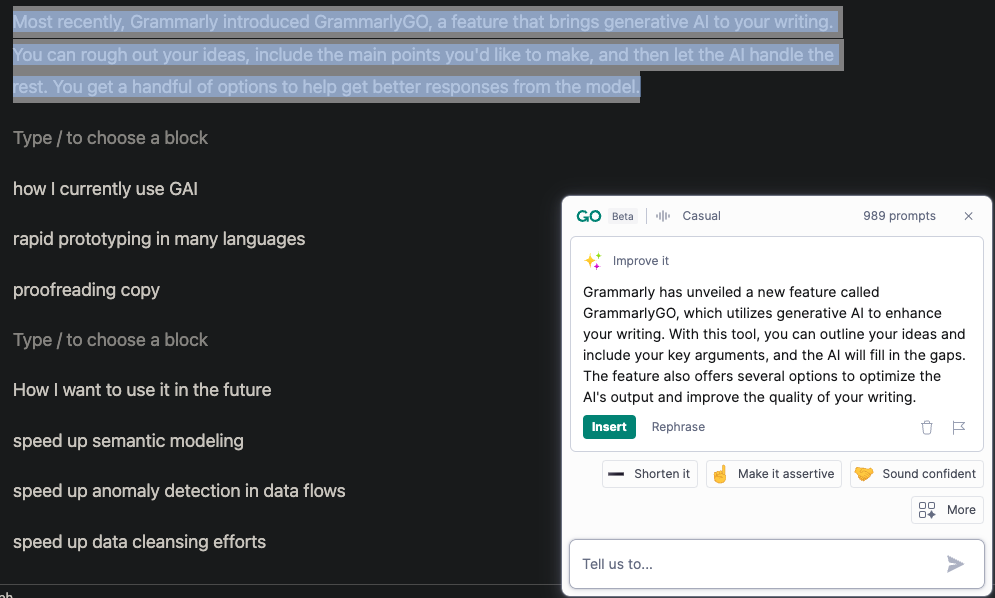
I usually use a casual voice on my blog; when writing statements of work, I’ll switch to a formal and more direct tone. It didn’t take too long to get used to the extra feature!
Copilot
I’ve only used Copilot for a little over a year now. After just a few months in the beta period, I was hooked! As a consultant, I don’t have control over what languages can be at play in a client’s environment. It’s difficult keeping all the nuances of each language in your head, so I’d often stub a prototype out in a language I knew better and then hit StackOverflow for ways to convert it into a client’s desired language. That research time adds up.
But Copilot gives me a better way. I can add a comment and let the bot code it. While the code it returns isn’t perfect, it gets me to the 80% mark on the first try. From there, I can continue to work with the code to get it the rest of the way.
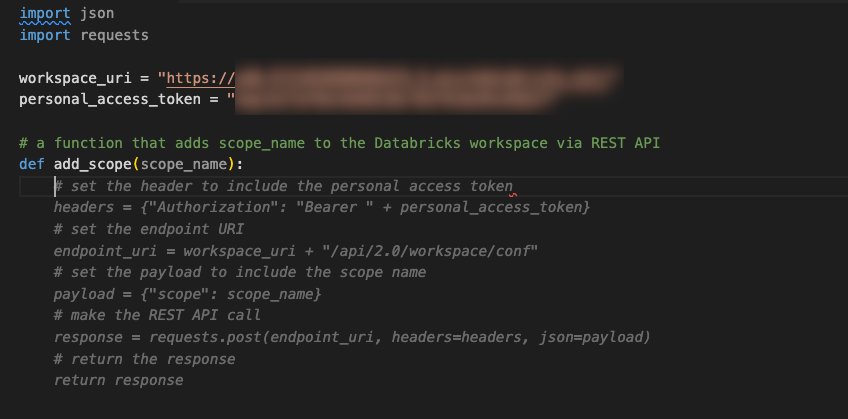
Several months back, I was working with a client new to Databricks. We learned they hadn’t started using the secrets during our initial assessment. One reason for this is that Databricks hasn’t provided a complete API to secrets through dbutils.secrets. You can get secret values and list scopes through Python, but you cannot create scopes or add secrets. You can only do that through their REST API. As a result, I needed to show them how they could add the missing functionality to their internal code library.
I created a Python file to start the demo and then added the JSON and requests libraries. I knew that I would need my Databricks URI and a personal access token to access the REST API endpoint. Before promoting this code to production, we’d secure the personal access token in secrets so it wasn’t hard coded in the final library.
Then I had to type the comment and hit enter—Copilot filled in the rest.
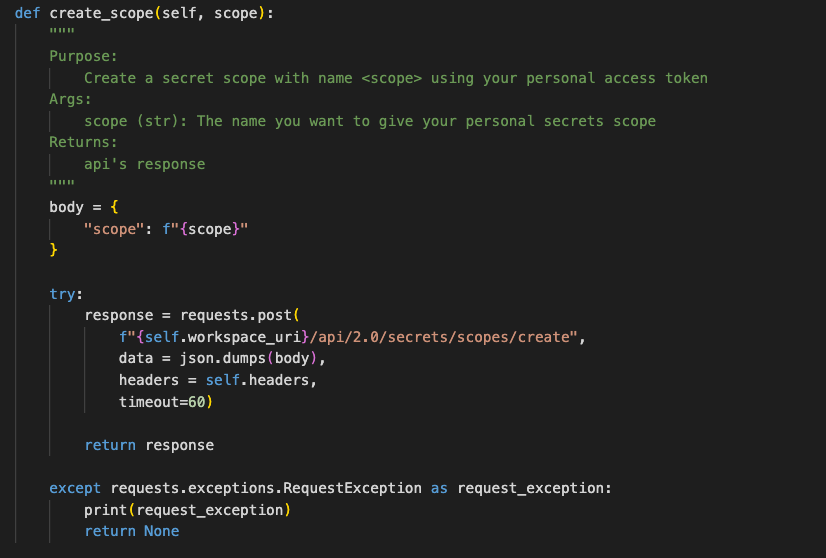
Hit enter or TAB, and the code is inserted into your file. That’s not bad, but it’s missing try/catch logic. It’s also missing a timeout parameter on the post. But for 5 seconds of typing, it’s not bad. In the end, we added the code to a class to come up with this final version of the code. The class handled the URI and personal access token secrecy.
Future use cases I’m researching
I’m excited to find my next tool to help ease my workload. I’m excited to learn more about how we could build tools that can help in the data pipelines themselves. Anomaly detection seems to be a natural fit for detecting deep data pipeline failures. Something like a given tenant database has suddenly sent far fewer data than usual, or the data values in a given pipeline are highly unusual. Similar approaches could be applied to cleanse data as it moves through remediation pipelines. Even more interesting is the possibility of extracting semantic meaning from data by studying the metadata and the data as it streams into our raw zones.
If you are interested in learning more about how AI can help you with data engineering or if you are using AI to help you with your daily work, please feel free to email me. I would be happy to chat with you and answer any questions you may have.